Java 多线程学习笔记
概念
线程和进程
线程:Thread,是操作系统中能够进行任务调度的最小单位,一般来说是一条单独的任务,比如 bilibili 的视频解码器是一个线程,音频解码器是一条线程,弹幕显示器是一条线程,它们被一起包装在 bilibili 这个进程中,作为正在运行的应用程序。因此线程指的是进程中的一个单一顺序的控制流,一个进程中可以有多条线程,每条线程执行不同的任务。
进程:Process, 是指计算机中运行的程序,直观体现是任务管理器中的一个个进程,进程本身不是基本运行单位,而是线程的容器,多个运行不同的线程组成了一个进程。而一个 Java 程序就是一个 JVM 进程,这个 JVM 进程中,主线程执行 main() 方法,而在 main() 线程中,又可以调用其他的线程实现多线程。
并发和并行
并发:Concurrent,是指计算机能够具备处理多个任务的能力,反义词是顺序。顺序执行时只能在执行完一个任务之后才能执行第二个任务,而并发可以“同时”执行多个任务,无论这个是通过将多个大任务分为一个个小任务,然后快速切换执行不同大任务的小任务运行实现的“同时”执行,还是真正的用两个处理器核心,不同核心专注执行不同任务实现的同时执行。两种方法都被成为并发。
并行:parallel ,是指计算机真正意义上的同时处理两个任务,这在物理基础上需要 CPU 的两个单独的核心,然后使得两个任务的不同执行在同一时间在不同的核心上面被执行。并行是并发的一种情况(上面实现并发的第二种方法就是并行)。
线程调度
分时调度:所有的线程轮流使用 CPU 的使用权,平均分配每个线程占用 CPU 的时间。
抢占式调度:根据优先度来分配线程的使用时间,优先度高的占用时间长,Java 采用此机制。
两者的特点
对于一个复杂的应用程序,肯定是需要实现并发,也就是不同的小任务同时执行,比如 bilibili 的弹幕任务,视频解码任务和音频解码任务等。这些小任务的同时运行实现方法就是多个进程或者线程之间并发,亦或者两者一起。
创建一个进程的开销要比创建一个线程开销大很多,而且一个进程内部的多个线程之间的通信 开销很小(因为访问的是同一个变量),进程与进程之间的的通信开销就要大很多。
正是因为进程之间有一定的隔离,所以稳定性比多线程好很多。多个进程之间崩溃是互不影响的,而一个进程里面的线程一旦崩溃,这个进程中的所有线程都要受到影响。
创建线程
main 线程
在一个 Java 程序被执行的时候,是从 main 函数开始执行的,而 main 函数被执行的时候就是一个单独的线程,它的名字就叫做 main 线程。
首先 main 函数的代码会被放到内存的栈空间中,然后将这个空间和 CPU 建立一个桥梁,CPU 可以通过此桥梁读取此内存空间中的数据和指令,然后执行它。而这个桥梁就是线程,名字为 main 线程。
在执行 main 线程的时候,main 函数可能有创建一个新的线程的代码,当 CPU 运行 main 线程到此部分的时候,就会按照线程指令执行,开辟一个新的内存空间,放入数据和指令,然后建立一个自己到这个空间的桥梁命名为 func1 线程,用来读取数据和执行放入的指令。这就成功的在 JVM 进程的 main 线程中新建了第二个线程 func1 到此进程中,实现了多线程。
这个两个线程组成的多线程是可以实现并发的,也就是两个线程 main 和 func1 的任务可以“同时”运行。这是单独一个线程无法实现的,单独一个线程只能顺序执行里面的指令。
线程建立过程
方法一:继承Thread
建立一个新的线程的方法就是新建一个类,继承于 Thread 类。然后在子类中重写 Thread 类里的 run() 方法,这个方法里面是需要新线程同步执行的代码。然后调用子类实例的 start() 方法,就成功的建立了一个新的线程,此线程和 main 线程并发执行。
1 | public class test { |
注意只有 start() 方法会开启线程并在新线程中执行 run() 中的方法。
方法二:传入Runnable
Runnable 是一个接口,实现这个 Runnable 接口只需要重写一个 run() 类,和继承 Thread 的重写 run() 几乎相同,不同的是 ,这里实现了线程和执行内容的分离。
1 | public Thread(Runnable target); |
直接在 Thread 的构造方法中,传入一个实现了 Runnable 的类的实例即可,然后调用 Thread 实例的 start() 方法启动并运行线程。
1 | public class test { |
比如上面方法传入的 Runnable 实现类就是一个匿名类,传入 Thread 的构造方法之后创建线程,再用实例 Xorex 的 start() 方法启动线程。
方法三:使用 Lambda 表达式
其实方法三和上面的方法二本质上是一样,唯一的不同就是使用了 Java8 新加入的 Lambda 表达式简化了代码。
首先忽略 λ Lambda 这个奇奇怪怪的名字,这个代码简化其实贼简单,就是个实例化匿名类的语法糖,它可以将所有能够逻辑推断出来的东西全部省略,但只有一个限制,就是这个类里面只能有一个方法,下面是使用 Lambda 表达式简化的线程建立:
1 | public class test { |
上面就是最简状态的实例化匿名类的代码,少了 new Runnable() 因为编译器可以通过 Thread 构造方法接收 Runnable 接口对象来推断出来这个类实现了 Runnable 接口。少了重写方法的签名 public void run() 是因为这个接口只有一个抽象方法等待重写,肯定是它。少了{;} 大括号和分号是因为里面只有一句语句,当然如果有多语句的话,还是需要 {} 来确定语句范围,需要 ; 来将多个语句分隔开来。至于剩下的 Lambda 表达式标志 () -> 其中 () 表示是一个方法,里面用来填写参数(可省略类型,因为可以根据抽象方法推断出来),没有参数就空着。而 -> 则是 Lambda 的根本标志符号,必不可少。
如果需要返回参数呢,有两种方式,一种是单表达式语句,这种就按照最简写即可,而会自动返回表达式计算的结果,如果是多语句,则需要自己写 return 返回值。
下面是对 Lambda 表达式的三种情况总结:
1 | ( params ) -> expression |
第一种举个例子:(int e) -> e*e 因为是一个 expression 直接返回这个表达式计算值。
第二种举个例子:(int e) -> e=e*e 是一个单语句 statement 则返回空 void 。
第三种举个例子:只要有大括号,就必须手写 return 语句。
1 | (int e) -> {return e*e;} |
Lambda 表达式里面的各种特性还有很多,以后遇到了会好好总结一下的!
Thread 类
上面只是利用 Thread 类新建了一个线程,而 Thread 类中还有很多好用的方法。
1 | public Thread(String name); //构造方法,设置线程名称 |
- 首先对于
setPriority方法并不能保真正优先执行此线程,而是增加了此线程被执行的概率,总体来说被执行次数会高于优先级低的线程。 - 其次是
sleep方法是一个静态方法,在被当前线程执行的时候,当前线程就会暂停执行对应毫秒,因为此方法被执行肯定是在某个线程中被执行的,所以暂停的线程也肯定是它所在的线程。 - 最后
currentThread方法会返回当前执行的线程对象的引用,需要用 Thread 来接收,本质上和正在运行的线程是一个实例。
线程状态
对于一个线程来说,它也有自己的声明周期,在 Java 中,一个线程的声明周期有以下几种:
New新建状态:线程处于正在被生成的过程。Runnable就绪状态:线程处于可以被执行状态。Timeed Waiting等待时间状态:线程处于基于时间的等待状态。Waiting等待状态:线程处于等待唤醒状态。Blocked阻塞状态:线程处于无法被执行状态。Terminated死亡状态:线程处于被终止的状态。
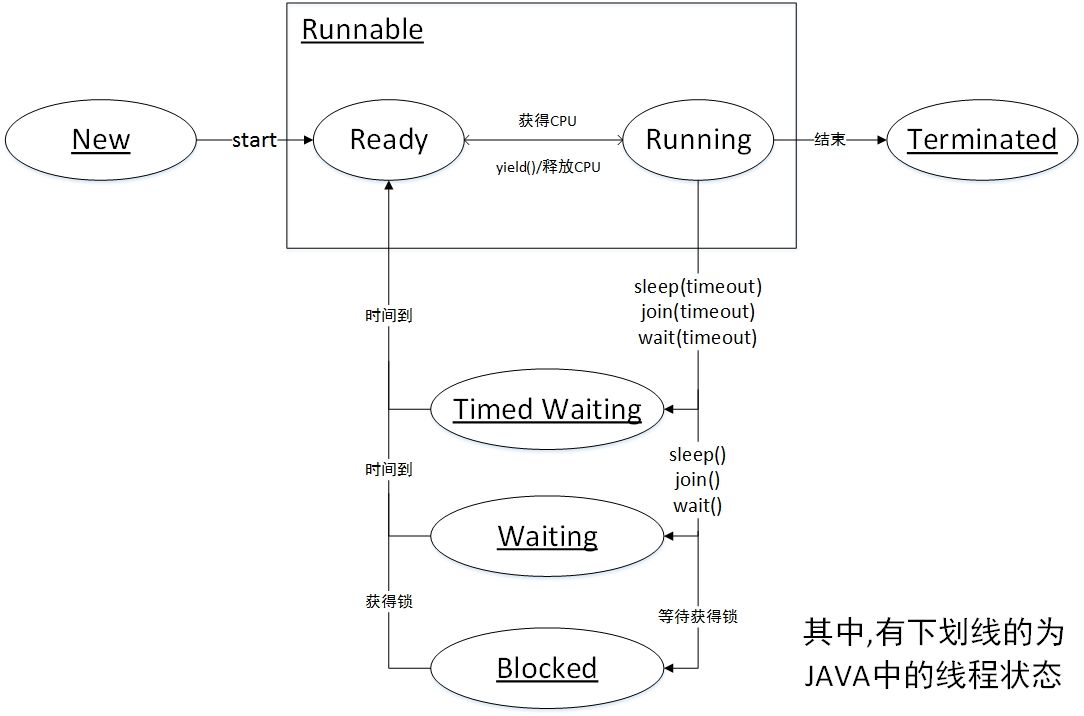
Runnable 状态
其实 Runnable 是两种子状态的一个概括,总的来说是可被执行状态分为就绪状态和被执行状态,也就是上图对应的 Ready 和 Running 状态。
我们不需要关心程序处于 Runnable 的时候,具体是在等待 CPU 调度还是正在 CPU 上运行,因为这是我们无法控制的,分配计算资源完全是操作系统干的,作为上层的应用程序我们无法干涉,所以就统称为 Runnable 可运行状态。
Waiting 和 Timed Waiting 状态
这两个状态基本相同,都是主动的放弃 CPU 被执行权,主动进入了等待状态。不同的是,Waiting 是无限期等待,需要被另外一个线程唤醒才能进入 Runnable 状态,而 Timed Waiting 是主动放弃我们设定的一定时间的 CPU 被执行权,过了这段时间,它会自己醒来,进入 Runnable 状态。
Blocked 状态
这个状态被称为阻塞状态,无法进入 Runnable 并不是因为主动放弃,而是无法获得执行权,或者说此线程被锁上了并且钥匙不在自己的手上。一旦此线程拿到钥匙,就会解锁进入 Runnable 状态。
线程安全
出现原因
多线程虽然很棒,不仅仅能通过 CPU 的快速切换实现“同时”执行多个连续任务,还能利用 CPU 本身硬件支持的多核多线程来真正同时执行多个线程,大幅度提高计算效率。比如 R5 4500U 就拥有六个核心,对于一个任务开六个线程可以让这六个核心同时去处理它,从而获得六倍的运行速度。
但是要知道对于处理器在运行语句的时候,不知道快速切换或者多核心实际运行位置所在之处。当多个线程需要同时对统一数据进行写入的时候,就会导致线程安全的问题。硬核一点,看一个语句:
1 | n=n+1; |
如果有两个线程同时对 n 变量进行上述语句的运行,因为不知道啥时候就丧失了 CPU 运行权,由另外一个线程运行,所以就可能出现下面的运行情况,在 Thread1 执行完 ILOAD 指令之后,丧失 CPU 执行权,由 Thread2 执行:
1 | ┌───────┐ ┌───────┐ |
两个线程两次执行 n=n+1 ,但是 n 的值只加了 1 ,这就是因为线程在读取写入数据的不同步导致的,这可是个大问题。我们再看一个代码:
1 | public class test { |
上面代码在同时执行 Th1 和 Th2 两个线程的时候,都会对同一个数据 count 进行读写操作,因为线程执行权切换可能发生在 count– 和输出 count 之间发生,所以看输出结果就会发现顺序是乱的,这就是因为线程代码不同步造成的,
线程同步,也就是一个线程中,某个过程应该连续同步完成,不允许中断。而实现线程同步,就需要将同步代码上锁,保证只有一个线程有钥匙打开并执行它,其它线程无法打开执行。
1. 同步代码块
一种是使用同步代码块这种语法将需要同步执行的一些代码框到里面,然后加上一个锁,只有拿到钥匙才能执行里面的内容,只需要保证钥匙的唯一性,就可以保证在同一时间,因为只有一个线程拥有钥匙,所以只有一个线程会执行锁里面的代码。当里面代码执行完毕之后,会将钥匙随机传给下一个线程,这个线程打开自己的锁,执行锁里面的代码。在这里,锁就是 synchronized 关键词,它锁住了代码块里面的代码,钥匙就是参数 key ,它需要是一个唯一的实例,用来解锁并执行内部代码。
1 | synchronized(Object key) { |
举个例子:
1 | package Java; |
上面就将同步代码使用 synchronized 语句上锁,然后设置字符串实例 "Xorex" 作为钥匙(在运行时常量池中是唯一实例,所有线程共享此实例)。在代码执行的时候,只有拥有钥匙的线程才能打开锁执行代码,锁代码执行完毕之后,会释放钥匙,释放的钥匙会随机传给下一个线程,注意可能会出现自己传给自己的情况,毕竟是随机传。
锁的实现原理:
2. 同步方法
同步方法和同步代码块的使用原理是一模一样的,但是不同的是这里将 synchronized 修饰词词用于某个方法的签名,这样在调用这个方法的时候,默认为这个方法里面的代码上了锁,只有此线程有钥匙才能解锁执行,比如:
1 | public synchronized void Eat() { |
因为不能传 key 参数,所以这里面的钥匙是不能自定义的,是固定的。
对于像上面一样的普通方法,key 为拥有此方法的实例 this,所以只要不同线程调用同步方法的实例是同一个,就能实现此方法的线程安全(别两个线程都 new 了这个对象去调用方法就行,这样同步了个寂寞)
而对于静态方法,因为和实例无关,只和类有关,所以 key 为此类的 Class 实例(这个由于类加载机制,一个类在堆中的 Class 实例是唯一的,并且全线程共享,所以能保证同步)
3. 同步锁 Lock
同步锁是一个接口,它的作用和 synchronized 有一样的地方,但是 Lock 的功能更强大,至于强大的功能以后再说,先看 Lock 接口的内容。
1 | void lock(); //开始获取锁,如果其他线程已经占用,则等待 |
大概就先了解这几个就可以了,需要注意的是这个是不会自动返还锁的,所以一旦在获取锁之后的代码里面,遇到了异常,就会中断代码,后面的释放锁操作就无法执行,所以在使用 Lock 的时候,需要配合这 try-catch 语句,将 unlock() 放到 finally 里面。
实现 Lock 接口的唯一类为:ReentrantLock,使用:
1 | import java.util.concurrent.locks.Lock; |
可重入锁
在 synchronized 同步代码块或者同步方法的地方,只要这个线程获取了唯一的钥匙,那么遇到相同的锁,都可以打开,比如:
1 | synchronized("Xorex") { |
这样的代码,最内层的代码一定是可以执行的,因为两个锁的钥匙相同,只要获取了第一个锁的钥匙 "Xorex" String 实例,那么第二个锁也因为有了钥匙可以打开。这样的锁叫作可重入锁。
产生死锁
死锁是因为两个线程在等待钥匙的时候,资源获取进入僵局,使得无法结束等待的情况称为死锁。
比如:两个线程,分别持有钥匙1和钥匙2,有钥匙1的同时在请求钥匙2,有钥匙2的同时在请求钥匙1。两个线程都进入了等待钥匙的状态,而自己持有的钥匙无法释放,导致了对方也陷入僵局。
一旦出现了死锁,只能停止执行代码,所以一定要尽力避免出现死锁的情况。
变量的多线程安全
对于多个线程对同一个变量进行操作的时候,因为 CPU 缓存的原因,变量经过更改之后是放在缓存中的,从缓存写入到内存的时间是不确定的。所以可能一个线程更改了数据之后,另外一个线程从内存中读取的还是旧的信息。为了保证涉及到多线程的数据的安全,可以在声明变量的时候添加关键词 volatile 不稳定的。标志完之后,所有对此数据的修改都会立刻写入内存中,保证其他线程的读取正确。
线程池
普通线程池
线程池就是线程的集合体,通过将线程保存在线程池中来反复利用已经有的线程。因为单独的一个线程的新建和销毁都需要消耗很多资源,所以这样将线程集合在一起,需要了就给他分配任务执行的方式能很好的管理线程。
新建线程池是通过 Executors 类的三个静态方法来返回一个 ExecutorService 接口的实现实例,一共有三种线程池:
1 | newFixedThreadPool(int nThreads) // 固定数量线程池需要输入参数线程数量 |
通过静态方法得到一个 ExecutorService 接口实现类的实例之后,调用 submit(Runnable) 并传入一个 Runnable 实现实例之后线程会自动运行。
最后需要调用线程池的方法 shutdown() 来关闭线程池,不然 Java 程序不会结束运行。
1 | package Java; |
反复线程池
当线程任务需要不断地重复执行的时候,就需要反复线程池了,接口为 ScheduledExecutorService ,而获取线程池的实例还是依靠 Executors 类的静态方法,不过这里只需要找名字里带有 Scheduled 的即可。
1 | ScheduledExecutorService Xorex=Executors.newScheduledThreadPool(12); |
拿到了一个反复线程池之后,自然要分配任务并且设定反复执行的时间之类的参数。这里 ScheduledExecutorService 接口启动线程方法变成了好几个,对应不同的反复模式:
延迟执行设定,delayTime 之后开始运行,执行 Runnable。
1 | schedule(Runnable,int delayTime, TimeUnit.SECONDS); |
固定速率执行设定,delayTime 之后开始运行,每次执行完任务每隔 RepeatDelayTime 之后再次重复执行任务。
1 | scheduleAtFixedRate(Runnable,int delayTime,int RepeatDelayTime, TimeUnit.SECONDS); |
固定时间执行设定,delayTime 之后开始运行,每隔 RepeatStartTime 重启线程任务,不管此线程是否执行完任务,都会重启线程,重新执行。
1 | ses.scheduleWithFixedDelay(Runnable,int delayTime,int RepeatStartTime, TimeUnit.SECONDS); |