MySQL-00-基本概念
关系型数据库 RDBMS
RDBMS Related DataBase Management System,关系型数据库。
MySQL 的关系型,体现的就是不同的表之间,是有数据关系的,一个表将学号和姓名绑定,其他表将班级和姓名绑定,通过这样的方式,表和表之间就建立了关系,可以进行复杂的查询。
对应的非关系型数据库,就是数据之间彼此独立的,比如 Redis。
表与表的关系
- 有四种:一对一关联、一对多关联、多对多关联、自我引用
一对一关联
在实际的开发中应用不多,因为一对一可以创建成一张表。
举例:设计
学生表:学号、姓名、手机号码、班级、系别、身份证号码、家庭住址、籍贯、紧急联系人、…- 拆为两个表:两个表的记录是一一对应关系。
基础信息表(常用信息):学号、姓名、手机号码、班级、系别档案信息表(不常用信息):学号、身份证号码、家庭住址、籍贯、紧急联系人、…
两种建表原则:
- 外键唯一:主表的主键和从表的外键(唯一),形成主外键关系,外键唯一。
- 外键是主键:主表的主键和从表的主键,形成主外键关系。
一对多关系
- 常见实例场景:
客户表和订单表,分类表和商品表,部门表和员工表。 - 举例:
- 员工表:编号、姓名、…、所属部门(多)
- 部门表:编号、名称、简介(一)
- 部门表的一条记录,对应员工表的多条记录。
- 一对多建表原则:在从表(多方)创建一个字段,字段作为外键指向主表(一方)的主键
多对多
要表示多对多关系,必须创建第三个表,该表通常称为联接表,它将多对多关系划分为两个一对多关系。将这两个表的主键都插入到第三个表中。
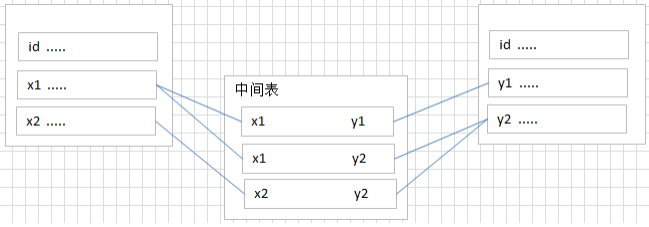
- 举例:学生-课程
学生信息表:一行代表一个学生的信息(学号、姓名、手机号码、班级、系别…)和 3 是一对多关系。课程信息表:一行代表一个课程的信息(课程编号、授课老师、简介…)和 3 是一对多关系。选课信息表:一个学生可以选多门课,一门课可以被多个学生选择。(在这个表中,体现了 1 和 2 的多对多关系)1
2
3
4学号 课程编号
1 1001
2 1001
1 1002
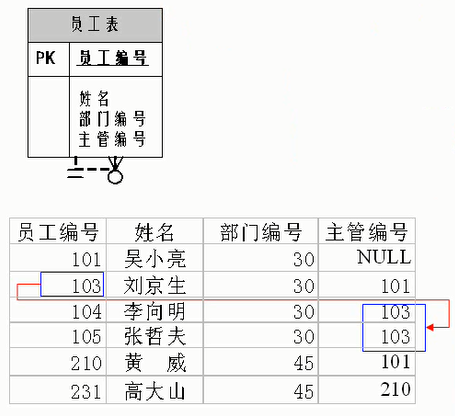
自我引用
一个表的某一列数据,成为这个表的另外一列数据的引用。比如下面的员工的主管编号就是引用本表的员工编号,是表内的自我引用。
MySQL 目录结构
重点目录结构有三个:
/etc/mysql/conf.d存放配置文件。/logs存放 MySQL 的执行日志文件。/var/lib/mysql存储数据库的数据。
语言分类
SQL语言在功能上主要分为如下3大类,定义、操作和控制:
DDL(Data Definition Languages、数据定义语言),这些语句定义了不同的数据库、表、视图、索引等数据库对象,还可以用来创建、删除、修改数据库和数据表的结构。
- 主要的语句关键字包括
CREATE、DROP、ALTER等。
- 主要的语句关键字包括
DML(Data Manipulation Language、数据操作语言),用于添加、删除、更新和查询数据库记录,并检查数据完整性。
- 主要的语句关键字包括
INSERT、DELETE、UPDATE、SELECT等。 - SELECT是SQL语言的基础,最为重要。
- 主要的语句关键字包括
DCL(Data Control Language、数据控制语言),用于定义数据库、表、字段、用户的访问权限和安全级别。
关键词执行顺序:
1 | from |
比如,对于我们手写的 SQL 语句:
1 | select <select_list> |
会这样处理:
- 第一步:加载 from 子句的前两个表计算笛卡尔积,生成虚拟表 vt1;
- 第二步:筛选关联表符合 on 表达式的数据,保留主表,生成虚拟表 vt2;
- 第三步:如果使用的是外连接,执行 on 的时候,会将主表中不符合 on 条件的数据也加载进来,做为外部行
- 第四步:如果 from 子句中的表数量大于 2,则重复第一步到第三步,直至所有的表都加载完毕,更新 vt3;
- 第五步:执行 where 表达式,筛选掉不符合条件的数据生成 vt4;
- 第六步:执行 group by 子句。group by 子句执行过后,会对子句组合成唯一值并且对每个唯一值只包含一行,生成 vt5,。一旦执行 group by,后面的所有步骤只得到 vt5 中的列(group by 的子句包含的列)和聚合函数。
- 第七步:执行聚合函数,生成 vt6;
- 第八步:执行 having 表达式,筛选 vt6 中的数据。having 是唯一一个在分组后的条件筛选,生成 vt7;
- 第九步:从 vt7 中筛选列,生成 vt8;
- 第十步:执行 distinct,对 vt8 去重,生成 vt9。其实执行过 group by 后就没必要再去执行 distinct,因为分组后,每组只会有一条数据,并且每条数据都不相同。
- 第十一步:对 vt9 进行排序,此处返回的不是一个虚拟表,而是一个游标,记录了数据的排序顺序,此处可以使用别名;
- 第十二步:执行 limit 语句,将结果返回给客户端
MySQL 对象
| 对象 | 描述 |
|---|---|
| 表(TABLE) | 表是存储数据的逻辑单元,以行和列的形式存在,列就是字段,行就是记录 |
| 数据字典(INFORMATION_SCHEMA) | 就是系统表,存放数据库相关信息的表。系统表的数据通常由数据库系统维护,程序员通常不应该修改,只可查看 |
| 约束(CONSTRAINT) | 执行数据校验的规则,用于保证数据完整性的规则 |
| 视图(VIEW) | 一个或者多个数据表里的数据的逻辑显示,视图并不存储数据 |
| 索引(INDEX) | 用于提高查询性能,相当于书的目录 |
| 存储过程(PROCEDURE) | 用于完成一次完整的业务处理,没有返回值,但可通过传出参数将多个值传给调用环境 |
| 存储函数(FUNCTION) | 用于完成一次特定的计算,具有一个返回值 |
| 触发器(TRIGGER) | 相当于一个事件监听器,当数据库发生特定事件后,触发器被触发,完成相应的处理 |