Python-08-线程、进程和协程
这章主要是:线程、进程和协程的介绍。
串行、并行:关注着程序是否有同时处理多个任务的能力。
阻塞、非阻塞:关注着程序是否处于什么都不干的等待状态。
同步、异步:关注着程序的任务调用,是按照顺序完成一个调用一个,还是一直调用并等待依次完成。
线程
全局解释锁 GIL
Global Interprator Lock 全局解释锁,因为 GIL 的存在,导致 Python 在一个时间内只有一个线程被执行。
Python虚拟机执行方式如下:
- 设置 GIL
- 切换进线程
- 执行下面操作之一:
- 运行指定数量的字节码指令
- 线程主动让出控制权
- 切换出线程(线程处于睡眠状态)
- 解锁 GIL
- 进入 1 步骤
采用 GIL 的原因是 Python 虚拟机采用引用计数法来标记垃圾回收。如果不加全局锁 GIL 的话,不同的线程在一个进程单位下,可以引用同一对象资源。那么并行访问就会可能导致引用计数的 线程不安全,所以才用 GIL 变成串行执行(引用是单个字节码)。
线程安全
需要注意的是,GIL 是解决 引用计数 的线程不安全,并不会防止其他资源访问的线程不安全问题。比如下面的代码:
1 | import threading |
n+1 这个代码的指令是多条组成,虽然是串行,但是线程丢失执行权时间不确定,就有可能有线程安全问题。
1 | LOAD_GLOBAL 0 (n) |
多线程
创建线程:thread = Thread(group=None, target=None, name=None, args=(), kwargs={}, daemon=None)
- group 为以后 Python 新特性 ThreadGroup 准备的
- target 填写要运行的函数名,不带括号 callable
- name 线程名 str
- args 非可变参数,而是元组变量,按照函数的参数顺序依次填充被调用函数 tuple
- kwargs 非可变参数,而是字典变量,按照 参数名:参数值 填充被调用函数 dic
- daemon 是否为守护线程 boolean
1 | from threading import Thread |
线程池
将若干固定的操作交给若干个线程执行,非常方便。
从 concurrent.futures 里面导入 ThreadPoolExecutor
1 | from concurrent.futures import ThreadPoolExecutor |
submit() 函数会返回一个 Executor,可以从中获取线程执行结果 result()。
记得要 submit() 完所有的任务之后,再去获取结果哦。
进程
多进程由于 GIL 的存在,没有办法并行运行,所以为了充分利用 CPU 的多个核心,就只能采用 多进程 的方式了。
当然,一个进程中可以开启很多线程来共享内存资源。
基本语法
从 multiporcessing 中导入 Process 类。
Process __init__ 的参数和 Thread 是一样的。
1 | from multiprocessing import Process |
无限引用问题
上面有一个问题,就是为什么 Process 的启动必须在 main 中。
这是由于在开启一个新的进程的时候,需要资源是相互隔离的,所以要复制一份到新的进程中。
那么在导入本 py 文件的时候,如果线程创建不写在 main 中,导入过程就会执行线程创建,就会再次复制资源到新的进程并在导入,然后进入死循环。类似于循环引用,不过是我引用我自己。
所以写了 __main__ 中之后,就不会在导入过程中不停开新的进程然后再导入了。
进程池
用法和线程池差不多,下面是大体结构:
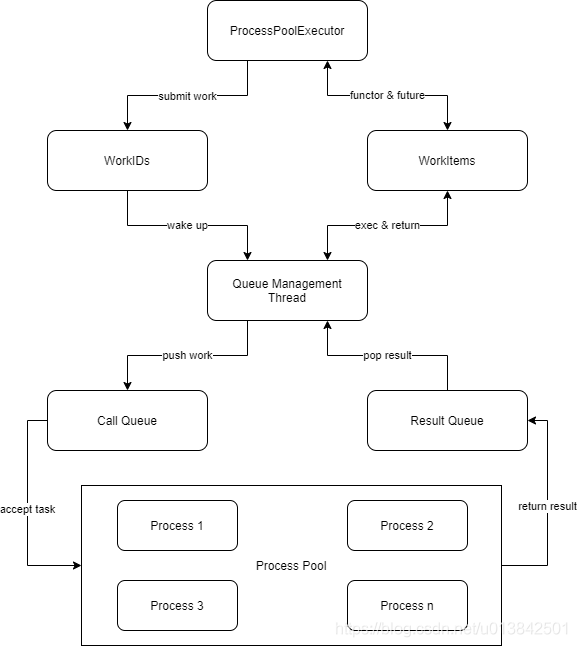
1 | from concurrent.futures import ProcessPoolExecutor |
submit() 函数会返回一个 Executor,可以从中获取线程执行结果 result()。
协程
这里的异步主要是指 Asyncio 对所有处于 IO 状态的代码进行切换异步处理,等到 IO 加载完成之后,再继续回来处理代码,减少因为等待 IO 浪费的时间,等待 IO 是可以并行等待的。
这里的 IO 有很多,比如打开文件进行文件读写,网络请求与发送等等。通过 async 进行协程任务标注,通过 await 进行协程调用。
基本语法
async 表示此任务是异步的,在协程事件队列可以随意调用然后等待事件结果返回。在函数前面加上此前缀,函数会会变成一个协程对象。
await 表示此处调用了可等待的任务,只有发来了等待结果才能继续往后面运行,是协程对象中的代码支持的功能。
下面的代码借助着协程的 异步非阻塞,实现了单线程 3s 的执行:
1 | import asyncio |
需要注意的是,协程不同于线程,启动一个线程之后,是不影响主线程的继续执行的。但是启动了一个协程,主协程会等待新协程执行完毕之后,再去执行后面的代码。
所以下面方式创建多个协程运行是会 阻塞 运行的:
1 | await function() |
应当使用将一个协程对象通过 asyncio.create_task() 转化为任务之后,组成一个任务列表 tasks[],然后借助这 asyncio.wait(tasks) 将这些任务全部加入到事件循环中之后,再启动异步执行。这样这些任务就可以再 IO 的时候被事件循环控制跳转,实现非阻塞执行。
事件循环
协程在单线程中实现 IO 的异步非阻塞借助的是 事件循环 event_loop。
每一个协程对象都是一个事件,被添加到事件循环之后,可以被 asyncio 的控制下,遇到 IO 就切换到另外一个事件去执行,直到等待到 IO 的执行结果,再跳转回来执行。每一个对象执行的跳转,都在事件循环中。
所以我们执行一个协程的时候,需要借助着 asyncio.run() 创建一个事件循环,然后把参数:协程对象 加入到事件循环中,启动事件循环的执行。
协程对象每运行到 await,就会把它加入到事件循环中,以协程的方式执行它,当它执行完毕之后响应执行结果,然后跳转回来继续执行 await 后面的代码。
async with
异步的上下文管理器,比如异步的网络会话想要通过 with 来进行上下文管理的时候,就需要加上 async with,来保证异步资源在被管理的时候,可以执行内部的异步代码。比如:
1 | # async with 可以用 await 调用后面的资源生成,也可以用 await 调用最后的 close 实现管理过程的异步调用 |
async for
用来迭代 异步可迭代 对象:
一个异步可迭代对象(asynchronous iterable)能够在迭代过程中调用异步代码,而异步迭代器就是能够在 next() 方法中调用异步代码。
1、一个对象必须实现 __aiter__ 方法,该方法返回一个异步迭代器(asynchronous iterator)对象。
2、一个异步迭代器对象必须实现 __anext__ 方法,该方法返回一个 awaitable 类型的值。
3、为了停止迭代,__anext__ 必须抛出一个 StopAsyncIteration 异常。
上面的内容不用管,你只需要知道如果被迭代对象是一个 异步可迭代 对象,那么就用 async for 即可。
异步协程库
要通过协程的方式 异步非阻塞 执行 IO 任务,就要要调用的 IO API 也必须是 async 类型的协程对象。如果对应的 IO API 没有异步实现的话,就只能借助多进程来完成了。
aiohttp
1 | async with aiohttp.ClientSession() as session: |
aiofiles
1 | async with aiofiles.open(fileName, mode='w',encoding='utf-8') as f: |