Python-06-异常和代码管理
异常捕获
基本结构
1 | try: |
异常信息
我们捕获到了对应的异常实例之后就需要对异常获取信息处理:
- e.args:返回异常的错误编号和描述字符串;
- str(e):返回异常信息,但不包括异常信息的类型;
- repr(e):返回较全的异常信息,包括异常信息的类型。
异常继承结构
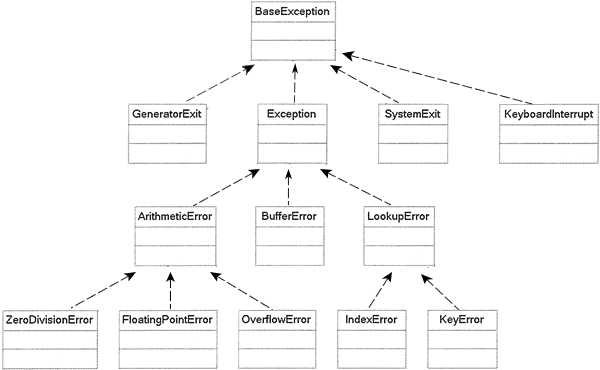
如果要自己实现异常的时候,就一定要找对上层异常去继承。
异常
我们可以手动抛出异常 关键字 raise
可以在任何地方使用 raise,抛出一个异常的实例。
1 | raise e # 在 except 语句里面抛出捕获的异常 |
查看异常信息
导入 traceback 模块,调用方法:
traceback.print_exc()控制台输出内容traceback.print_exc(file=open('filename','a'))文件 filename 中输出内容
就直接在 except 里面调用即可。
日志系统
Python 自带 logging 模块可以使用,
基本设置
感觉确实没有 Java 的日志系统使用起来更方便一点。导入 logging 模块之后,需要用 baseConfig() 进行最基本的设置,常用的参数如下:
1 | filename: str | PathLike[str] | None = ..., |
主要集中在 level (日志显示最低等级),format 输出日志格式,这两个上面。
1 | import logging |
日志级别
我们只要调用 logging 对应的日志输出函数,里面填充日志 message 内容
| 级别 | 对应的函数 | 描述 |
|---|---|---|
| DEBUG | logging.debug() | 最低级别,用于小细节,通常只有在诊断问题时,才会关心这些消息。 |
| INFO | logging.info() | 用于记录程序中一般事件的信息,或确认一切工作正常。 |
| WARNING | logging.warning() | 用于表示可能的问题,它不会阻止程序的工作,但将来可能会。 |
| ERROR | logging.error() | 用于记录错误,它导致程序做某事失败。 |
| CRITICAL | logging.critical() | 最高级别,用于表示致命的错误,它导致或将要导致程序完全停止工作。 |
具体的日志系统如何使用,以后写项目再研究。
模块
Python 一个 py 文件就是一个模块,可以通过 import 导入进来,然后通过文件名作为此文件代码的命名空间,来访问里面的变量和函数。
import
import 有两种写法:
import module_name as alias将模块 module_name.py 导入,并起别名 alias(可以不起别名),然后就可以别名作为命名空间访问里面的变量和模块,就像类一样。from module_name import func/var将变量或者函数单独导入,这样访问就不需要指定命名空间,用名字就可以了。
当然如果遇到开头是空格或者数字的模块名,那就这样导入:
__import__(modulename:str) 这是等价于 import 的内建函数。
__name__
在运行程序的时候,会首先看所有 import 的模块,将这些模块的代码逐一经过解释器执行。但是对于模块中一些不想被导入是执行的代码,可以通过判断命名空间来决定是否执行,内建模块自带 __name__ 变量。
在运行一个 Python 文件的时候,如果执行文件里面的代码,这个内建模块变量 __name__ 的值为 __main__,当执行到 import 导入模块的时候,会改变 __name__ 值为模块名字,然后再解释执行模块里面的内容。
所以当时直接运行模块文件的时候 __name__ 值为 __main__,我们可以运行一些代码执行,当时作为模块导入另外的文件的时候,值就会变成文件名,就可以不运行这些代码。
1 | if __name__ == '__main__': |
模块文档
只需要用 ''' 包裹在文件开始即可。然后再调用的地方可以用 模块名.__doc__ 获取这些字符串里面的内容。
模块查找
这里的模块定位查找:
在当前目录,即当前执行的程序文件所在目录下查找;
到 PYTHONPATH(环境变量)下的每个目录中查找;
到 Python 默认的安装目录下查找。
这些目录都可以在 sys.path 中输出查看。
当 Python 程序找不到模块的时候:
向 sys.path 中临时添加模块文件存储位置的完整路径;
将模块放在 sys.path 变量中已包含的模块加载路径中;
设置 path 系统环境变量。
模块封装
当用户通过 import 导入模块命名空间来访问模块成员的时候,如果想要限制一些方法的访问,可以使用
_或者__作为开头限制访问。当用户通过 from xxx import * 进行全部导入的时候,可以通过内建列表
__all__来设置允许被导入的成员名字。
1 | __all__ = ['fun1','fun2','var1','var2'] |
导入本质
本质上就是创建了一个模块名的变量,类型是 <class 'module'>, 将模块里面的代码,交给了这个变量,通过这个变量来访问模块成员。
包 package
包是对模块的一种封装管理,是一个文件夹,文件夹的名字就是这个包的名字。这个文件夹里面可以包含另外一个包,也可以包含若干个模块。
基本结构
一般来说,一个 package 的文件夹下面都会有一个叫做 __init__.py 的模块,在单纯的导入包的时候,本质上就是导入了这个包的 __init__.py 模块。
比如我们可以新建一个文件夹叫 my_package,然后里面管理着两个模块 module1.py 和 module2.py,那么这个完整的 package 如下:
1 | my_package |
导入 package
因为 package 相对于 module,多了一层概念,那么再导入的时候,也需要多一层 package 的名字:
有三种方式导入 package 中的 module:
import 包名[.模块名 [as 别名]]from 包名 import 模块名 [as 别名]from 包名.模块名 import 成员名 [as 别名]
- 对于第一种,如果只导入包名的话,其实是导入了
__init__.py这个模块了。并不是同时导入 package 里面的所有 module。导入 包名.模块名 之后,除非起一个别名,否则还是用 包名.模块名 这样的命名空间来访问。
利用 __init__.py
实际上对与包的使用远远没有这么麻烦,比如在使用 requests 包的时候,可没对包里面的各种模块控制导入。这是因为第三方提供的包中,一般都会包的 __init__.py 模块中完成了整个包对外暴露的成员的控制,导入 __init__.py 就等于导入了整个包的功能。
因为导入包名其实就是导入了 __init__.py,所以只要在这个模块里面导入需要的成员,那么外界就可以借助着 __init__.py 也就是导入包名完成访问了。
在 __init__.py 编写导入模块代码的时候,写法和外部导入是一样的,不同的是包名使用 . 来代替,比如 requests 里面:
1 | from . import utils # 在自己的包 request 中导入模块 utils |
不过访问 __init__.py 里面导入的成员,肯定要加上包名这一层命名空间。