Git学习笔记
Git 概念
分布式与集中式
其实这两个在版本控制系统里面区别就是历史版本存放位置。
集中式版本控制系统单的历史版本是存放在一个固定的服务器上面的,每次写代码只是拿到其中的一个版本,写完之后提交。这样一旦服务器挂掉,就无法工作了。
而分布式版本控制系统的历史版本是所有人都在本地有一份的,服务器的作用是用来方便大家同步本地的版本(合并别人的修改),这样即使服务器挂掉,可以一对一的同步代码,甚至不同步也可以,手里有整个历史版本,可以回退,不影响工作。
所以这就是 Git 分布式版本控制系统的强大之处!
Git 历史
Git 的来源是 Linus 不满意其他人写的版本控制系统,自己花了两个星期写的。牛的牛的!
Git 工作原理
Git 将文件分为三个区域:
工作区的文件 -> git add -> 暂存区的文件 -> git commit -> 本地库的文件 -> git push —> 远程库
工作区其实就是我们写代码的地方,写好一个代码文件之后添加到暂存区,等到整个版本的很多代码文件都写好并加入暂存区之后,就可以将暂存区里面的所有内容作为一个版本更新提交到本地库里面了。本地有了一个版本的记录,就可以推送到远程库里面,让所有人都看到这次版本更新了。不过具体的实际原理还是看后面的分析吧。
Git 基础命令
git status
用来查看当前工作状态,告诉你当前分支 On branch master ,哪些暂存区文件被修改了还没有提交 Changes not staged for commit,哪些文件没有被记录到暂存区 Untracked files。
git add
git add FILENAME 将 FILENAME 文件加入暂存区中,实测加入到暂存区之后的文件,修改之后可以不经过 add 直接 commit 该文件。
git commit
git commit -m "INFO" 将暂存区的所有文件的都提交到本地库中并附上说明 INFO。
git commit -m "INFO" FILENAME 将工作区的 FILENAME 文件提交到本地库并附上说明 INFO。
所以如果指定文件,是从工作区找的,如果不指定文件,则只会 将修改后使用 add 命令提交到暂存区的文件们 提交到本地库!
当然如果不想指定文件,也想将所有被追踪的工作区文件提交到本地库,而不经过暂存区,就直接用命令: git commit -m "INFO" -a
git commit –amend
amend [ə'mɛnd] 修正改善,故名思意,这个命令是用来修复上一次提交的。
说是修复提交,其实就是合并提交,当你发现上一次提交不足以作为一个版本记录之后,就可以先将代码修改到一个版本记录级别,然后使用命令 git commit --amend -m "AMEND_INFO" 这样回将这次新修改的和上次提交的修改合并为一个新的修改并提交,提交信息为新设置的 AMEND_INFO。
git log/relog
relog 是用来查看简单的版本记录(只包括版本号,版本名,当前版本和当前指向分支)
1 | $ git reflog |
log 会现实更加详细的内容,包括日期和提交者签名。
1 | $ git log |
git reset
git reset 主要用于当前工作分支的版本回退,格式为:git reset --MODE VERSION_ID。
用 MODE 级别的模式,回退到 VERSION_ID 的版本(将本分支指针指向对应的版本号)。下面是 MODE 的对应的几种模式:
- –soft 等同于将状态恢复到执行
commit之前(也就是撤销 commit,工作区代码修改完成,全部放到了暂存区,就差 commit 的状态。) - –mixed 等同于将状态恢复到写好了代码,但是没有 add 和 commit 的状态。(工作区内容不变,暂存区变为指定的版本)
- –keep 比较特殊,工作区的内容根据版本重置(恢复到对应版本状态),但是暂存区还是原来的,和 mixed 相反。
- –hard 将所有状态都同步到当时版本的状态,工作区,暂存区,都是目标版本执行完 commit 之前的状态。
Git 分支系统
git branch
git branch -v 查看所有的分支。
git branch BRANCH_NAME 创建一个新的分支,BRANCH_NAME 。
git checkout BRANCH_NAME 查看另外一个分支(将指针移动到 BRANCH_NAME 分支上面)
分支合并
git merge BRANCH_NAME 会将分支 BRANCH_NAME 合并到当前的分支上面。
当两个分支的同一个文件的相同行都有修改的时候(不同行被两个分支分别修改没关系,两个修改都会被保留),自动合并就会出问题了,需要我们手动处理冲突。
出现合并冲突之后,打开冲突的文件,会自动标注冲突的地方,也就是 … 的地方就是冲突的文本。
1 | <<<<<< HEAD //开始分隔符 |
只需要将分隔符删掉,两个冲突文本选择要保留的,就可以保存了。保存完之后只能添加到暂存区,然后统一提交。(提交 + 文件名的方法不可以,会报错找不到哪个文件)
Git 游离 Head
checkout 就是很简单的查看的意思,就是为了查看某个版本的状态。当然我们一般都是查看某个分支所处的状态,然后用 reset 不断切换分支所属的版本。那能不能不切换分支所属版本,也能查看某个版本的状态呢,答案是可以的,让 HEAD 指针不指向分支,而是指向版本(某次提交的版本号)
比如 git checkout 7ea3922 就直接到了 7ea3922 提交过后的版本状态了,但是这个时候 HEAD 不在任何一个分支上面,是游离的,也就是 Detached HEAD。
我们到了游离分支也可以发展自己,不断的 commit,或者当作一个分支使用,不过由于都是版本名,不太好进行版本控制,还是直接在游离分支上建立一个真正的 Branch 并取一个名字,方便对这个分支进行版本控制。
文件忽略
对于一些不需要版本控制的文件,比如数据库配置文件,IDEA 配置文件,.class 编译的文件,则可以都配置成 git.ignore,然后声明到 .gitconfig 文件里面,让 Git 放弃对这些文件的版本控制。
而我们设置的 git.ignore 和 .gitconfig 都是在 C 盘的 Users/Xorex 目录下面的,做的是一个全局的配置。
.ignore 使用 # 做注释,支持正则表达式,一行为一句表达式。
1 | # Compiled class file |
然后将这个文件路径在 .gitconfig 中添加配置:
1 | [core] |
一定要多次比对配置信息啊,千万别写错,写错了就执行不了!!!
代码托管平台
基本操作
在 Github 上面创建完一个仓库之后,有两种连接方式:
- HTTP 连接:
https://github.com/Administrator-Xorex/Git.git - SSH 连接:
git@github.com:Administrator-Xorex/Git.git
因为连接太长,所以可以建立一个别名:git remote add ALIAS https://xxx.xxx ALIAS 就是我们给后面连接设置的别名。
推送本地库某个分支到仓库里面:git push ALIAS BRANCH_NAME 需要指定推送的分支名。
拉取仓库代码:git pull ALIAS BRANCH_NAMEs 需要指定拉去的分支名。
克隆仓库代码:git clone https://xxx.xxx/xx.git 然后就会在当前目录下面将仓库所有代码用仓库名作为文件夹保存下来,克隆之后会创建项目地址的别名 origin。
对于多人协作的时候,自己编写完代码需要先将远程库里面的代码 pull 下来,解决完冲突之后,才可以将自己的代码 push 上去。
HTTPS 连接每次都需要输入 Github 的密码,解决方案一个是使用 Windows 自带的 Credential Manager 添加验证,另外一个是在 Git 里面保存一定时常的密码,只需要输入命令:git config --global credential.helper store 即可,下次输入完密码就被保存了。
或者配置好 SSH 的公钥到 Github 中,走 SSH 连接。
团队协作
第一种团队协作方式就是将另外一个人加入到自己的团队中开发,这就需要 Github 里面的团队邀请机制了,把别人邀请到自己的团队里面,然后给予他 pull 和 push 的权限,一起开发。
这个只需要在 Manage access 里面添加用户就可以了。
另外一种就是让另外一个团队复制一份仓库,然后他们开发完之后,请求让仓库主人将开发完的复制仓库拉去到自己的主仓库中。解决完冲突之后,另外团队的开发内容就合并到主仓库里面了。
复制使用 fork 来将仓库拉过来一份,开发完点击 pull request 发起请求。仓库主人审核完代码自会后,统一请求,向被 forked 出来的仓库发起 pull,从而合并代码。
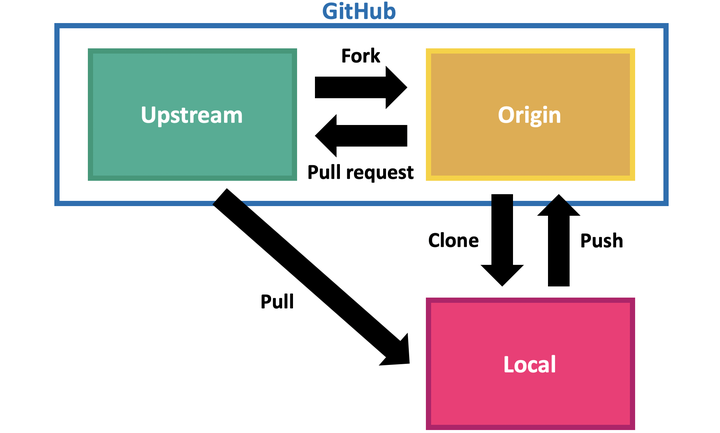
比如上面的图片就是对项目 UpStream 进行的一个多团队开发过程。
先 fork 出来一个 origin 的仓库,然后在 clone 到本地,经过开发之后,向项目 UpStream 发起 Pull Request 请求,项目管理员同意之后,会 pull origin 仓库,完成代码合并。
和 IDEA 整合
分支合并
原理和命令都是相同的,都是选择分支,然后让其合并到当前的分支上面。
Git 实现原理
Git 的实现原理就是通过 HEAD 指针和分支指针所指向内容的变化,来描述当前分支的变化和当前分支所在历史版本的变化。然后每一次 commit 都记录下来此次提交每一行的变化记录,然后根据这个变化记录来计算不同版本的文本内容。
先看看 Git 的目录:
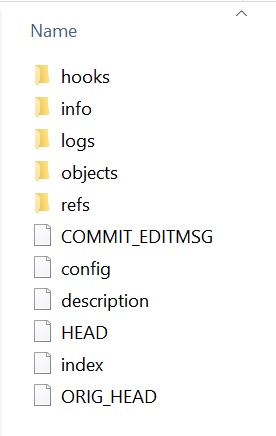
hooks 目录
这个文件夹里面保存了下面这些东西:
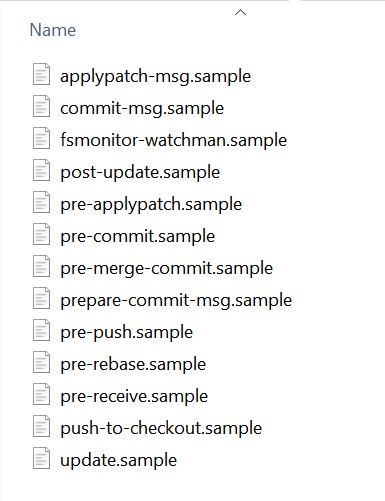
这些都是一些脚本,在执行 git 一些命令的前后执行,所以被称为钩子,来钩在命令的前后,做一些检查之类的工作。
info 目录
里面只有 exclude 一个文件,用来配置不纳入 git 管理文件信息。
logs 目录
记录提交的提交记录,下属有一个 HEAD 文件和 refs 文件夹,HEAD 文件记录所有的提交记录,而 refs 文件夹分别保存着不同分支的提交记录文件。
1 | | -- refs |
在我们调用 git reflog 和 git log 命令来获取提交记录的时候,就是从这些文件里面读取的。
objects 目录
执行完 git add 之后,文件的更改信息(每一行的变化)就会被存储到 objects 目录了,会根据版本名的前两位做一个类似于 HashTable 的分组优化。
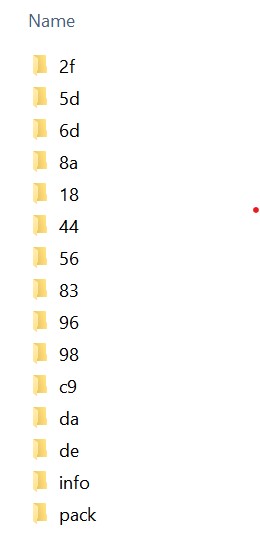
然后里面的文件名为历史版本名(其实就是内容计算 SHA1 作为文件名),文件内容就是此版本文件的每一行变化记录,根据记录来计算不同版本下文件的内容,
当我们执行了 git gc 或者将代码 push 到远程仓库之后,git 就会将这些零散的文件更改信息打包,放入 pack 文件夹里面,并在 info 文件夹里面的文件留下记录。
refs 目录
里面有存储着分支和标签的引用,用来记录当前 HEAD 指针指向的分支和标签内容。实际上根据 HEAD 指针找到当前分支以及当前分支所处的记录节点(历史版本节点)就是在这个目录里面的文件里保存的。
config 文件
主要是 Git 的一些配置保存的地方:
1 | [core] |
HEAD 文件
存储着当前位置的指针,表示当前所在的分支名称,内容为一个 ref 的地址,从 refs 目录里面找分支引用。
1 | ref: refs/heads/master |
目录文件的结果是当前分支 master 的记录节点名(其实就是根据内容计算 SHA1 作为文件名):
1 | 96e8d208240398683deb39dd4de2aeb576136ca6 |
index 文件
index 在 Git 里面是暂存区记录,并不是真正的暂存区。当我们使用 add 之后,会直接将更改记录添加到 objects 文件夹里面,然后在 index 文件里面留下来记录。commit 的时候是从 index 里面找到缓存区内容的索引信息。
add 和 commmit 命令分别做了什么
对于 objects 文件夹里面的东西,虽然名字都是 SHA1 生成的,但是还是有区别的,分为四类:
- Commit 包含提交人、日期、消息还有目录树,作为一个版本的快照。
- Tree 引用其他的 Tree 或者 Blob
- Blob 存储一个文件的修改数据
- Tag 存储某个提交的引用。
关系如下:
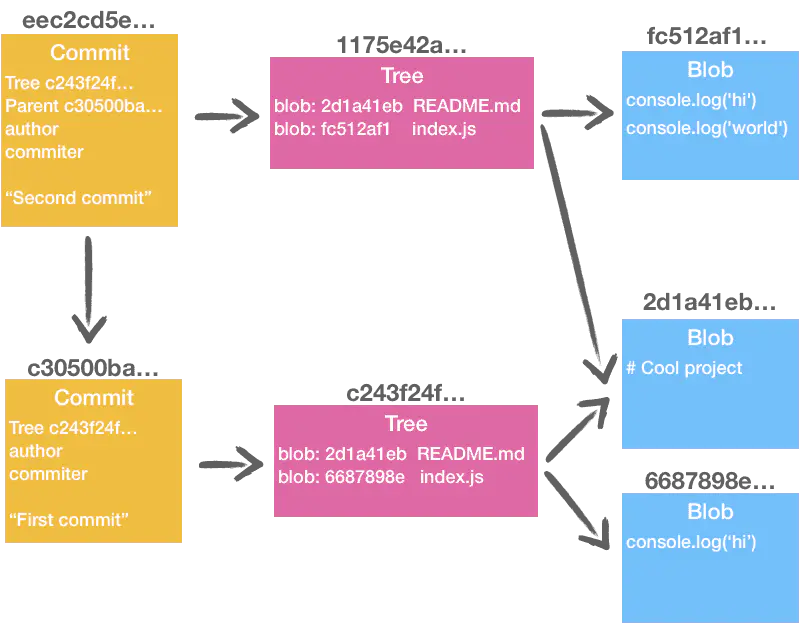
当我们执行了 add 命令之后,就会在 objects 生成 Blob 文件,文件的数量取决于 add 加入暂存区并修改内容的文件的数量。使用 commit 提交之后,会生成一个快照 Tree 文件,来记录本次提交所有文件修改记录的索引(SHA1 文件名)。生成完快照之后,会生成一个提交记录,里面包括快照的索引(SHA1 文件名),上一次提交记录的索引(SHA1 文件名),本次提交的作者签名(name 和 email),以及提交描述。
观察上面的图片,有一点点细节,那就是 Blob 文件并不会存储文件名,文件名是交给 Tree 文件保存的,所以一旦移动文件或者改名字,是认不出来的,只会被当作一个新的文件。其次是这个文件需要手动删除,也就是使用命令 git rm test.txt 将其从暂存区删除,不然从另外一个版本跳过来的时候,会根据快照重新生成这个文件。