MySQL 命令学习
《关于我高考分数太低不得不去转行搞信息安全这件事》
- 为什么随便什么事情加上书名号都能成为轻小说啊???
emmmmm,最开始其实是有点遗憾的,因为我原本以为我可以稳的不能再稳地进入CUIT的软件工程专业的,毕竟我比去年的软工最低分数线高了5000名,比CUIT最低分数线高了12000名,这还录不上就过分了!结果就真的很过分了,河南省的117w考生中还真的出了4个头比我还铁的人,然后我就来了CUIT的信息安全专业。
但是俗话说既来之则安之,都是IT类的专业,只要自己好好学,就肯定有出路的。再说这些东西其实都是靠自学,只要自学能力够了,转什么方向都很轻松,抱着这样的想法,我就来到了CUIT。
然后在网上开始搜索各种关于CUIT信息安全的信息,因为当时在报考志愿的时候根本就没有考虑过CUIT的信息安全专业(我真的还是太自信了QAQ),然后在知乎中了解到了CUIT的三叶草社团非常非常厉害,还找到了三叶草的招新QQ群,于是我就加了进去。
里面的学长非常热情,其中有学长在群里面问有人想要学Web吗,我回了一句我想学,然后就收到了学长的QQ好友申请,然后他就推荐了我看图解HTTP和了解HTML相关的知识。几天过后,他有把我拉进了一个Web的学习小组,布置了第一次的任务,这也是这篇MySQL命令文章的来源。来吧少年,努力成为一名优秀的安全工程师吧!
MySQL增加系列
CREATE:
- create database
创造一个名字叫name的数据库:
1 | create database "name"; |
- create table
创造一个名字叫 name 的表:
1 | create table "name" |
这里要注意的是如果不在想要加入表单的数据库中,可以在创建表单的同时,把表单直接加入想要加入的数据库中,具体的写法是把上面语句中的”name”代替为:database_name.table_name 这样就直接把表单加入到了指定的database_name里面了。
USE:
使用语句,用来选择数据库。
1 | use "DATABASE"; |
使用名为DATABASE的数据库。
SET:
1 | set "column" utf8; |
将列column使用utf8编码 (防乱码)
DROP:
- drop table 语句 删除表
1 | drop table "table_name"; |
- drop database 语句 删除数据库
1 | drop database "database_name"; |
Truncate:
用来删除一个表的数据,但是不删除这个表。
1 | truncate table "table_name"; |
SQL查看系列
VERSION:
用来返回数据库的版本信息。
1 | select version(); |
SHOW:
用来显示所有的数据库或者表。
1 | show databases; |
SELECT:
1 | select "*/column" from "table"; |
显示table表里面的所有列或者column列。
DATABASE()
配合着select食用,用来返回当前使用的数据库名字。
1 | select database(); |
DISTINCT:
distinct 不同,相异。
显示table表里的所有不重复的column列,加在column名称之前。(用于数据的去重)
1 | select distinct "column" from "table"; |
WHERE:
条件语句,显示出当column列里值等于0的数据,用于数据的过滤。
1 | select * from "table" where "column=0"; |
LIMIT :
只显示出来column!=0的时候,前2行的数据。等价于[1,2]的数据。
1 | select * from "table" where "column!=0" |
只显示出来column!=0的时候,第2行之后的2行数据,即第3,4行数据。
1 | select * from "table" where "column!=0" |
只显示出来column!=0的时候,第2行之后所有的数据。等价于[3,last]的数据。
1 | select * from "table" where "column!=0" |
AND&OR:
主要运用在判断语句里面,作为增加判断复杂度的语句:
1 | select * from "table" |
1 | select * from "table" |
上面就等同于if里面的&&和||啦。
ORDER BY:
排序语句,将要显示的数据按照自己要求的规则进行排序。
将table表里的数据,按照column列值进行排序,ASC为从小到大,DESC为从大到小,如果不写排序方式,则默认为ASC,从小到大。
1 | select * from "table" |
ASC全称ascend ,为升序的意思,即从小到大。
DESC全程descend,为降序的意思,即从大到小。
GROUP BY:
group by 语句用于结合聚合函数,根据一个或多个列对结果集进行分组。我们需要选择一个column列作为分组的依据,然后这个column中数值相同的数据将会被整合到一行数据中,被整合在一起的数据需要进行合并处理,不然就会报错。
也就是说,在 SELECT 语句中出现的元素要么为一个聚合函数的输入值,要么为 GROUP BY 语句的参数。
1 | select column1, aggregate_function(column2) |
这样,会返回一个列出所有不同column1的值为一行数据的表格,其中column1值相同的数据所拥有的column2的值会根据aggregate_function()的功能进行计算,然后出现在那行数据里。
HAVING语句!
需要注意的是,这里 where 语句是没有办法将 aggregate_function()返回的参数进行筛选的,因为在执行where的时候,聚合函数还没有工作,所以筛选只能使用在 group by 语句后面的having语句,通常来说having语句都处于命令的最后。
having其实是可以代替where来使用的,它甚至可以使用where不能使用的别名,比如 column1+column2 as column3 ,那么having就可以使用column3来筛选,但是where不行,where只能只用column1+column2。
但是有一点限制的是,对于select没有选中的数据,having是不能拿来用的,比如在语句 select column1,column2 from “table”; 中,后面的 having 语句就只能使用column1和column2来筛选数据,但是where可以使用没有被选中的column3来使用数据。
LIKE:
用于在where里面模糊匹配:
1 | select * from "table" |
%这个符号非常有灵性,%在哪一边,哪一边就可以模糊处理,什么字符都可以,这个like简直就是搜索利器啊。直接搜搜column列里面的数据有没有和KeyWord相匹配的。
同时Like语句 支持 or/and/ 逻辑哦!具体用法如下:
1 | select * from "table" |
Like 除了可以用 % 来模糊任意个字符,还可以用 _ 下划线,来之模糊下划线部位的字符。
IN:
where会用到,等价于 =
1 | select * from "table" |
下面是等价的写法:
1 | select * from "table" |
UNION:
Union用于合并两个select所选中数据的值,必须是两个表,并去重,如果不想去重,就使用UNION ALL 语句;
1 | select column1 from "table1" |
这样就可以把table1和table2两个表中的column1列和column2列的数据进行合并,然后去重之后返回,大概就和并集概念是一样的,但是要注意这两个列中的数据类型必须相似,比如都是字符串连个列都应该是字符串,如果是整形,两个列都应该是整形。
BETWEEN:
between A and B 是用来来选取A到B范围内的元素,注意这个区间在不同的数据库中的开闭情况是不同的,在MySQL中,这个是两边都闭的区间。
这条语句可以用在任何数据类型上面,如果所作用的数据是字符串,那么它筛选的区间是根据字符串的首字母进行筛选的。
1 | select * from "table" |
这个东西还能用来筛选日期,只要日期格式规范就行。
AS:
as是SQL语句中的别名,用来给原来的列或者由于运算新产生的列一个新的名字。
比如把两个列相加产生的新数据重新命名为 12sum:
1 | select column1+column2 as 12sum from "table"; |
在比如把合并的几个字符串产生的新字符串命名为 12add:
1 | select comcat(column1,column2) as 12add from "table"; |
SQL修改系列
INSERT INTO:
插入信息,insert into。
- 普通导入:第一行表名后面写列名,第二行Values后面写数据,注意如果要用单引号全用单引号,如果要用双引号全用双引号,需要保持一致性。
1 | insert into "table" (column1,column2,column3) |
- 批量导入:和上面一样,不过写多个括号,用逗号隔开。
1 | insert into "table" (column1,column2,column3) |
UPDATE:
用于更新表中已经存在的数据:
1 | update "table" |
当利用column0的值等于value0,来确定我们需要跟新的行,然后对这一行的column1和column2进行更新。
注意 where语句的存在非常重要,如果没有where,那么将会把表中的所有数据都更改,而不是指定数据。
DELETE:
用于删除表中的行:
1 | delete from "table" |
和上面的update一样,一定要注意where语句的存在,不然会把所有的行全部删掉,也就是删掉了整个表。注意Delete语句不支持单独删除某行某列的数据,只能删除整行数据。
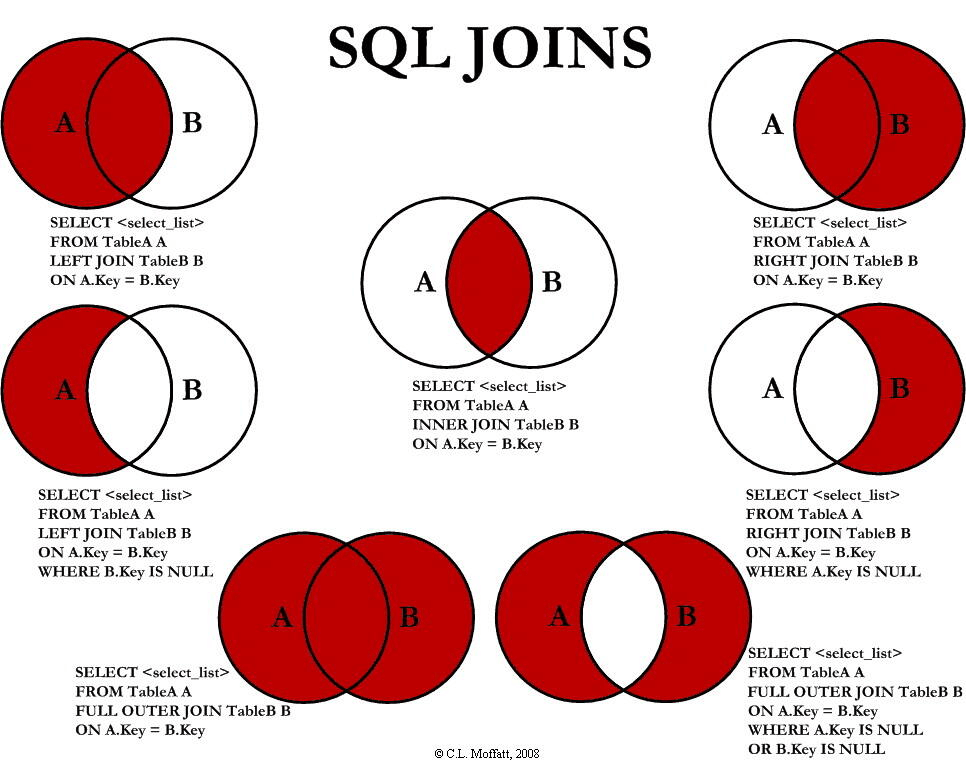
JOIN:
连接函数,所谓连接函数,就是将两个不同表的数据连接在一起,输出一个新的表,这个表是两个表合并的结果,注意如果需要使用JOIN,尽可能让两个表的数据类型是一样的,这样可以很好的保证数据合并之后的效果。
join的连接,需要一个桥梁,也就是两个表中,有一列的数据类型是相同的,我们就能通过column1的值和column2的值相同的两个表的数据合并成一行。
1 | table1 join table2 on table1.column1 = table2.column2; |
下面的图真的就是JOIN的全部精髓了:
INSERT INTO SELECT:
这是MySQL数据库使用的命令,用来复制一个表单的完整数据加入到另外一个表单,但是需要注意的是,如果直接复制,那么需要两个表的每一列的数据类型必须完全的对应。
当然大部分情况两个表的数据类型当然不可能完全一样啦,所以我们就可以进行将指定列的数据进行复制,只要保证指定列的数据类型一样就可以了。
如果想只复制一部分数据,那么和where语句进行搭配使用就可以了,具体的语法规则如下:
1 | insert into "table1" (column1,column2) |
SQL函数
concat()
- concat()
这个函数的作用就是将多个字符串连接成一个字符串,然后返回,如果里面有参数为NULL,那么返回的结果就是NULL。
普通版本的concat()的写法如下:
1 | select concat(column1,' ',column2,' ',column3) |
最后会返回将column1/2/3三列的值合并在一起,中间用空格隔开。
- concat_ws()
这个东西是concat()的升级版本,意思为concat with separator,它的又是就是直接规定了分隔不同数据的字符,不用手动间隔了。
1 | select concat_ws("separator",column1,column2,column3) |
上面三列数据合并的时候,会以 separator 为分隔符号出现在两列数据中间。
- group_concat()
这个就是concat()函数在group下面使用的函数了,当我们在使用group by 语句的时候,group_concat()就是一个聚合函数,作用就是把所有分到一组的数据聚合在一起,然后用逗号分隔开来。
截取字符串
- left()
这个函数是用来从左往右截取一定长度的字符串使用的,具体的用法就是left(string,length),string代表字符串,length表使要截取的长度。
- right()
和left同理,不过这个是从右往左截取字符串。
- substring()/substr()
这个函数是用来从特定的地方开始截取特定长度的字符串使用的。
用法:substr/substring(string,postion,length) 第三个参数length可以不填,如果不填的话,就直接截到尾了。 注意position可以填写负数,负数是直接按照倒数来算的。