10-19 考试总结
说在前面
emmmm这次考试啊,真的是爆炸了,炸的连渣都不剩,顿时觉得自己的DP已经弱的不能再弱了QAQ
首先是看成绩:
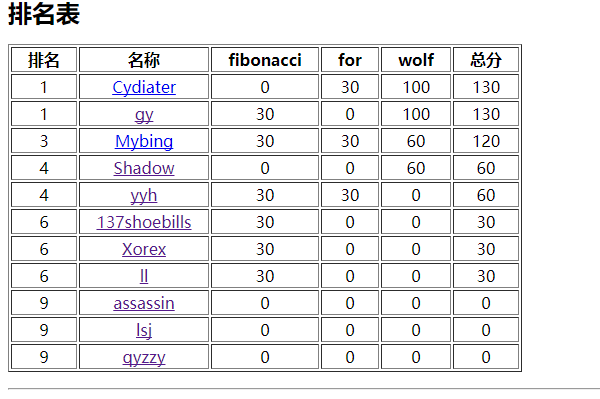
这个真的是炸的超级惨啊,直接GG……rank6-30分 :s
说说是为什么炸掉的,主要是T1,T1其实是非常简单的一个区间DP,自己在考场上面也是想到了的,但是当时苦于推DP式子,我还是对DP的理解不是太深,主要是没有想到状态转移的实质是什么。区间DP是如何完美转移式子的,还好想到了,但是写挂了。
式子是对的,但是状态转移错了,犯了一个不该犯的错误,F[i][j]在不断更新是建立在自己原来的值的,每次找到比F[i][j]更优的解然后更新,但是我转移都是当前转移方式的最优值,我的DP要重修了。
然后就是T3的暴力没写,其实是很简单的。
然后说说考试状态吧:
- 感觉这是一个非常失败的考试时间安排,对的超级失败。自己首先拿到了题目,然后看T1,看完题没有任何思路。然后继续看T2,找到了一些思路,但是实际上这个思路是错的,很容易就可以找到反例来推翻,但是也没有去找反例来验证结论的争取性……
- 于是我就快速写了错误的T2,然后开始看T3,这时候节奏还是不错的,发现T3可以用暴力写,但是自己更倾向于找正解,推了一个小时方程推不出来,这时候帆神已经写完T1开始写T2了,说T1非常简单。就有些慌了,赶忙看T1。想了想区间DP的模型,然后慢慢的推出了正解(虽然小小的错误导致了爆零)。写完T1之后和帆神对拍T2,完美打脸。
- 然后自己开始狂推T2,推了半个小时推不出来,慌忙写了30分的暴力,然后继续推,继续推,继续推。感觉这是我整场考试最大的败笔,T2自己的思路是错误的,但是自己一直在错误的思路上走,在错误的代码上面改,最后一直到考试结束也没有写出来。大约总共花费了2个半小时的时间
- 其实当时写出来了T2的暴力之后,看到时间不多而且推了很久应该调整思路或者直接写T3的暴力,自己还是太过于追求满分了,但是实际上在T2的思路上自己是错误的……有时候应该做出来取舍,虽然狂推T2有可能拿到100分,这可比T3暴力的30分高多了,但是如果一开始就错了,或者写挂了,那么就是0分了。我认为以后考试应该稳一些,宁可少拿分也不能不拿分。
最后改了T1之后拿到了130分……这要是NOIP岂不是真的GG……
关于题解,emmmmm 给你好了:
T1-狼
题目描述:
在某个游戏中,你接受了一个任务。这个任务要求你消灭𝑛只狼。这些狼排 成一排,每只狼都有两个攻击力𝑎和𝑏。如果你消灭一只狼,需要的代价是这只 狼的𝑎攻击力加上它旁边的狼的𝑏攻击力。每消灭一头狼,它两边的狼(如果 有)会并在一起,仍然保持一排。你需要求出:消灭所有狼的最小代价。
输入:
- 输入第一行为一个正整数𝑛。 输入第二行为𝑛个非负整数,按顺序表示每只狼的𝑎攻击力;
- 第三行为𝑛个非负整数,表示每只狼的𝑏攻击力。
输出:
输出一行一个整数,为最小的代价。
题解:
- 这个区间DP还是非常非常的简单的,emmmm,只不过自己已经很久没有写过DP了,然后有些不熟练,看来专项练习还是很有必要的……
- 这道题需要设置状态F[i][j]为从i到j的狼全部消灭需要的代价(边缘代价不计),然后我们可以从最开始的区间开始不停地合并,从长度为1开始不停枚举,然后枚举起始位置和合并方案。这里合并是两个区域合并成一个大区域,这里合并是分先后顺序的,也就是先消灭不同区域需要的代价是不一样,需要两个都计算一下,然后选出最小的,就是这两个区域合并的最小代价,注意,这里说的最小代价是从i到k和k到j的两个连续区域的合并的最小代价,而并非从i到j的代价,从i到j有很多种方案,是需要去最小值的。
- 代码就放在下面了,虽然没有人看,但是……留下来吧。
代码:
1 |
|
T2-斐波那契数列
题目描述:
斐波那契数列𝐹满足如下性质:𝐹- = 1, 𝐹0 = 2, 𝐹230 = 𝐹23- + 𝐹2。 对于一个正整数𝑛,它可以表示成一些不同的斐波那契数列中的数的和。你需要求出:有多少种不同的方式可以表示出𝑛?
输入:
输入文件中有多组数据。第一行为一个整数𝑇,表示数据组数。 接下来𝑇行,每行一个正整数𝑛。
输出:
输出𝑇行,为𝑇组数据的答案。
题解:
这道题真的是DP啊,不过看起来思路和我的思路差不多QAQ,只不过是用DP的形式表示出来,DP的状态转移可以全面的完整的把所有的状态记录下来,所以说,以后做题多想想DP式子,DP还是很重要的!!!
然后这道题的神奇之处就是在于状态的设置上面,我们可以利用贪心的定理,把这些数化为斐波那契数列组成的,转化的时候要求大的尽可能打,也就是从大到小枚举斐波那契数列,然后能化就化。然后a[i]表示第i次化成斐波那契数列是是斐波那契数列的第几项。
接下来设置状态,DP[i][1]为第i次化为斐波那契数列时,a[i]这个位置选择的时候的方案数,DP[i][0]为不选择的状态。然后我们就从后往前推:
DP[i][1]=DP[i+1][0]+DP[i+1][1];
DP[i][0]=(a[i]-a[i+1])/2*DP[i+1][0]+(a[i]-a[i+1]-1)/2*DP[i+1][1];
- emmmmm状态的起始状态为DP[Max][1]=1,DP[Max][0]=(a[max]-1)/2;
代码:
1 |
|
T3不会写就不写了QAQ