计组-存储系统
主存的简单模型
首先看一个主存储器的模型图:

存储元:存储一个高低电位的最小单位。
存储单元:多个存储元组成的集合。
存储字:存放在一个存储单元中的二进制代码组合,也就是一组数据。
译码器:将地址存储器中的读写地址翻译成主存的读取控制电路。
片选线:整个芯片的开关,用高低电平表示是否在工作。作用于控制存储容量的扩充。多个存储器芯片同时开,同时关,实现存储器每次取出的位数的扩充,位扩展(一个存储单元能存储的最长信息位)。多个芯片轮流开轮流关,实现存储器存储单元数量的扩充,字扩展(增加内存地址的范围,能存下更多条数据)。两者结合可以实现字和位同时的扩充。
寻址:按照地址寻找到在某处的操作数。寻址有很多中,比如按字节寻址(也就是 8bit 大小位一个地址),按字寻址(计算机字长大小位一个地址),等等。
RAM 分类
随机存储器 Random Access Memory,这里的随机存储意思是无论在存储器的任何位置写入数据,所需要的时间都为电流经过的时间,耗时基本相同。并不是写入的数据会随机分布的意思。大部分随机存储器的特点就是保存数据需要通电,一旦断电就会数据丢失。
RAM 为了减少译码器的控制电路的复杂度,往往将大量的存储单元编上行地址和列地址,这样能大大减少控制电路电线的数量并通过两次分别传入行地址和列地址来降低地址线的带宽,如下行地址器和列地址器:
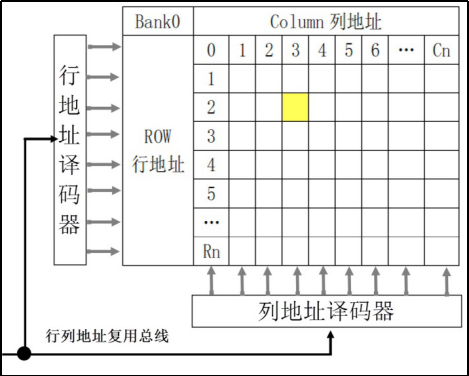
但是需要注意的是,因为将地址复用,并分两次分别传入行地址和列地址,所以就需要单独将确定存储器工作状态的片选线给拆分成行片选线和列片选线,分别确定行和列是否在工作状态。
- SRAM (Static) 静态随机存储器:
是使用双稳态多谐振荡器/触发器(设计复杂)作为数据存储的容器,读取数据不会破坏原有的状态。
这里的静态表示存储器只要保持通电,里面储存的数据就可以恒常保持。
特点是:能耗高,速度极快,成本极高,集成度较低,常常作为 Cache。
- DRAM (Dynamic) 动态随机存储器,
是使用电容/晶体管(设计简单)作为数据存储的容器,读取数据会破坏原有的状态。
这里的动态表示电容会漏电,所以需要定时充电才可以保持存储的数据。
特点是:能耗低,速度较快,成本较低,集成度较高,常常作为主存。
DRAM 读取刷新周期
- 内存刷新
因为 DRAM 的电容器一般来说只能在 2ms 内保证存储数据的稳定,所以说在 2ms 内,需要进行一次充电来刷新数据。刷新的过程为读取原有内容并按照原有内容进行一次完全充电,时间基本等同于一次读写周期
而由于主存的单次控制的读写每一次只能作用于一整行或者一整列,所以 2ms 内需要执行刷新电路 n 或 m 次。对于这么多的刷新次数,要么在 2ms 内分散开来刷新,要么在 2ms 内挑一个时间集中刷新完毕。
前者为异步刷新,后者为集中刷新。因为刷新的时候内存是无法被访问的,所以为了保证连续的性能,一般采用异步刷新:将所有的刷新任务均匀的分散在 2ms 内。
- 内存读取周期
A 表示 Address 表示读取地址。
CS 表示片选线,上面加上横线表示低电位为工作状态,高电位为无效状态。
Dout 表示读取数据总线,用于接收读取的数据。
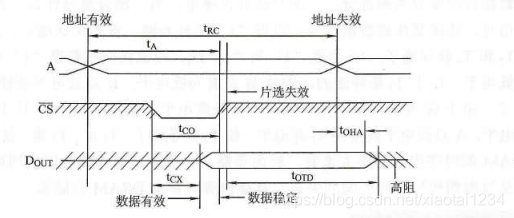
- 内存写入周期
Din 表示写入数据总线,用于提供要写入的数据。
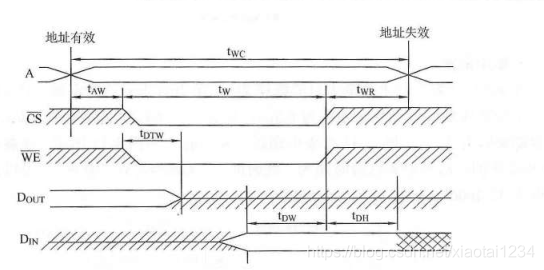
通过上面的读写周期的图可以看到,每一个过程并不是严格的同时进行,完成就关闭的,而是维持为了维持电路的稳定性做了一些等待。
ROM
ROM 指的是 Read Only Memory 只读存储器。
我们使用 CPU + RAM 作为一个主机就可以单独工作了,CPU 从 RAM 中读取指令并解析执行。但是因为 RAM 拥有断电就失去数据的特性,所以需要外界有一个能持久存储数据的介质存储操作系统运行执行,在主机开始运行之前,将持久存储的指令通过 IO 来写入 RAM 中,为 CPU 的最初运行提供指令。
而当时能够提供持久化存储的介质只有 ROM,也就是它们只能写入一次,之后只能读取。
但是市场越来越需要能够持久化存储的介质,并且对他们的写入要求也越来越高(能写入的话就可以自己存储数据了),于是随着科技的进步,逐渐发展出来了读和写都非常厉害的持久化存储介质。虽说这些介质能能够写入数据,但是由于历史原因、本身写入性能低于读取、和 RAM 有较大差别,这些介质仍然被称为 ROM。
MROM (Mask) 掩模式只读存储器 只有在出厂前的制造过程可以存储数据,出场之后就无法写入了,只能读,严格意义上的 ROM。
PROM (Programmable) 可编程只读存储器,出场后可以自己用专门的写入机器写入数据,写入之后同样是只能读取内容。CD-ROM 就是 PROM 的一种。
EPROM (Erasable Programmable) 可擦除可编程存储器,很有限的擦除重写,严格意义上已经脱离了只读存储器了。
Flash-ROM 基于 Flash 闪存技术的存储器,发展于 RAM,通过在电容间加入绝缘层和电感应读取数据解决了漏电的问题,变成了可持久化的存储介质。
HDD-ROM 机械硬盘,基于机械运动寻址和磁力存储,基本已经被淘汰。
SSD-ROM Flash 闪存的加强版,通过加入强大的读写驱动来大幅度提高读写性能,现在已经烂大街了。
需要注意的是 Flash 和加强版的 SSD 不仅仅属于 ROM,同样数据 RAM,因为它们作为半导体的电存储元器件也满足随机存储的特性:无论在存储器的任何位置写入数据,所需要的时间都为电流经过的时间,耗时基本相同。
SSD 为什么叫作固态硬盘呢,可能是 固体电容 在英语中为 Solid,被翻译成了固态的原因吧,反正各种命名都奇奇怪怪的。
存储器分类
随机存储器 这里专门指的是 RAM,也就是电脑里面的内存,大部分语境里面都不是指无论在存储器的任何位置写入数据,所需要的时间都为电流经过的时间,耗时基本相同,所以这里要记住!!!
顺序存取存储器 这里的顺序就是完全定义上的顺序,指的是像磁带这种,不能精确定位数据并读取的存储器,只能从头到尾顺序读取。
直接存取存储器 这里指能够计算定位并直接去相应位置存储数据的存储器,现代存储器基本上都支持这个功能。
相联存储器 是一种不根据地址而是根据存储内容来进行存取的存储器,里面内置了比较器。相联:两个无关之物之间的联系。
存储器性能指标
存取周期:存储器进行一次完整的读写操作所需要的时间。
主存带宽:又称为数据传输率或存储速度,每秒从主存中进出信息的最大数量,计算方式为:数据宽度/存储周期。
存储器的扩展
位扩展
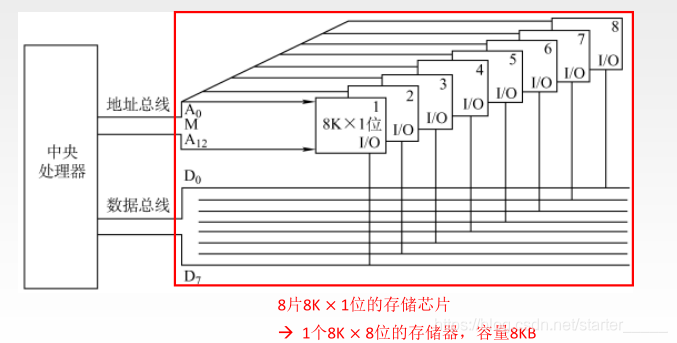
指增加存储器的存储字的长度,通过片选线控制多个存储器芯片同时开,同时关,实现存储器每次取出的位数的扩充,位扩展(一个存储单元能存储的最长信息位)。
下图表示将 8 个 1 位的存储器通过位扩展的方式扩展为字长为 8 的存储器,存储器芯片处于同时开的状态,其中 WE 表示的是读写控制总线:
字扩展
指增加存储器的存储字的数量,多个芯片轮流开轮流关,实现存储器存储单元数量的扩充,字扩展(增加内存地址的范围,能存下更多条数据)。
下图表示将四个 8k 个存储字数量的存储器通过字扩展为 24k 的存储字数量的存储器,其中译码器负责将传送过来的的存储器工作编号移码为对应的片选线电路:
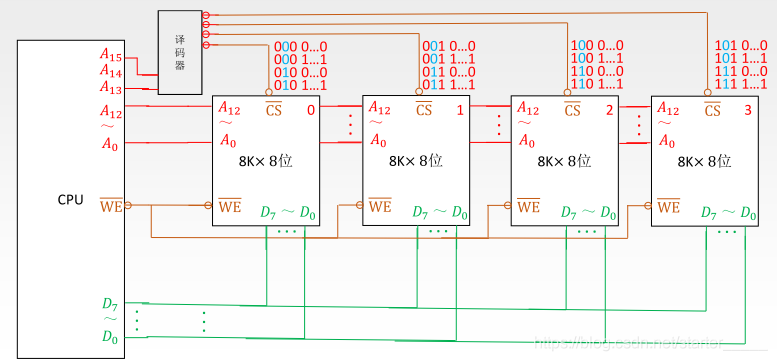
译码器的存在还有一个非常重要的作用就是让整个内存地址都有意义,地址的开头几位可以表示子存储器的编号,对应整个大存储器也保证了地址的连续性。
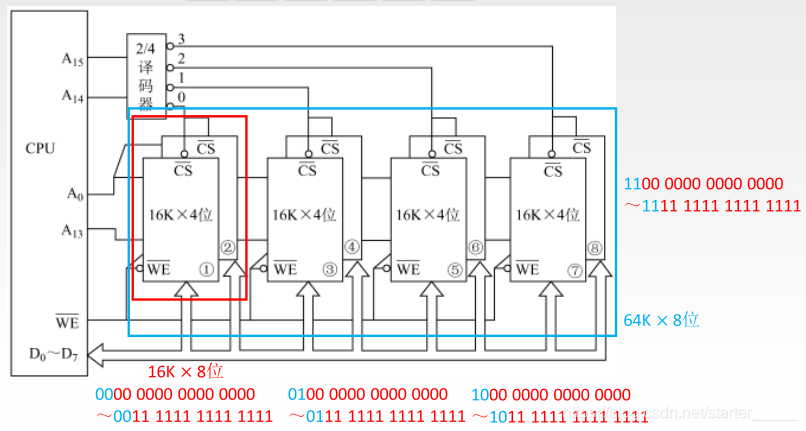
字和位同时扩展
将上面的两个结合在一起就可以了:
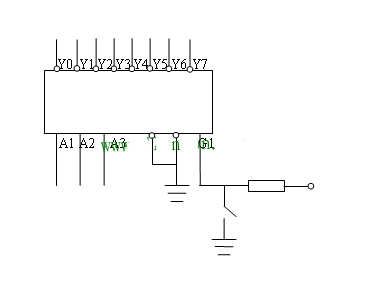
译码器
下面是一个常见的 38 译码器,A1 A2 A3 接收一个 3 位二进制数,然后能映射到对应的 Yn 的电位输出,常用于映射对应片选线来决定子存储器的工作状态。
需要注意的是译码器还有三个接口的使能端,带圆点要接入低电位(接地),第一个要接入高电位,只有 100 这样的使能端被接入,才能支持译码器的正确工作。否则译码器会将所有的 Y 都输出高电位。
存储器性能优化
因为 CPU 的性能提升实在是太快了,存储器也需要提高自己的性能来满足 CPU 才可以。
双端口 RAM
双端口 RAM 指的是一个 RAM 可以连接两个 CPU,和两个 CPU 进行数据交换,提高 RAM 的利用率。
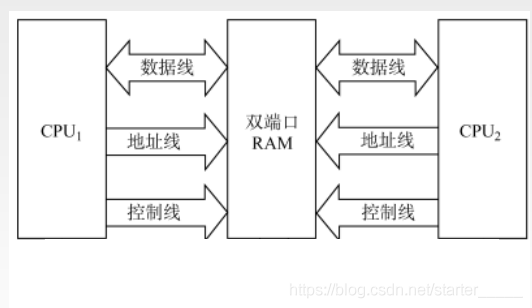
同时读取不同的数据:允许
同时写入不同的数据:允许
同时读取相同的数据:允许
同时写入相同的数据:禁止
同时一个读取一个写入相同的数据:禁止
这种双端口 RAM 其实也就大规模服务器(会有很多个 CPU)会用到,提高 RAM 的利用率,对于实际的读写性能提升并不明显。
多模块存储器
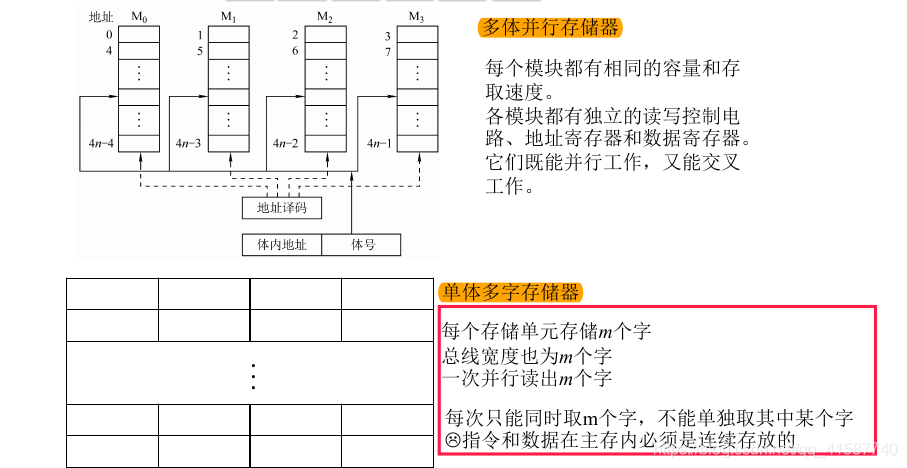
多模块存储器的性能优化有两个方向,正如上面的图一样,一个方向是实现多体并行存储器,另外一个方向是实现单体多字存储器。
多体并行存储器
多体并行看字面意思就是实现了一个有多个存储体能并行读取的存储器。
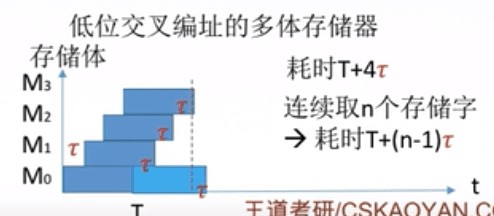
我们都知道在读取内存数据的时候整个读写周期为 读写时间+恢复时间 因为恢复时间有点耗时,那么多体并行存储器就想办法那它做文章。
看上图的地址编址,连续的地址是分散在不同的存储体中的,那么我们在读取连续的数据的时候,就可以先读取第一个存储器的 01 数据,拿到数据之后无需等待回复时间,直接去读取下一个存储体 02 数据。就像下面一样,避免在同一个存储体中连续读取数据,从而节约了恢复时间的开销。
实现在不同的存储体连续读写的只需要改变对原本地址的解析方式即可,截取最后几位(取决于存储体的数量)解析为体号,确定去哪个存储体中读写数据,而前面数据为存储体内地址,用来寻找具体的存储单元。
比如 00010110 这个地址,为寻找 22 号存储体,按照最上面的多体并行存储器的图,我们截取后两位为体号,却认为 2 号存储体。然后解析前面的 000101 确定为 2 号存储体的 5 号存储体,这样就找到了多体并行存储器里面的 22 号存储体了,也就是 00010110 地址。
单体多字存储器
看上面的图,单体多字存储器有点类似于位扩展,都是扩展了同时读取的数据长度,但是不同的是单体多字存储器是同时读取多个字。
扩张 MDR 和数据线路,来实现同时读取多个连续字的数据,从而提高读取速度,真正的并发处理。
实现原理就是电路一次读取一行的多个存储单元的信息,然后同时输出到数据线路,将这些连续的数据交给 CPU(其实是 Cache)。
一般来说优化都是上面两种存储器的结合体,多体多字并行存储器。
Cache 概念
因为 CPU 运算时间和内存的数据读取时间差异实在是太大了,导致了 CPU 大量的时间都浪费在了等待内存数据上面,为了提高数据读取效率,这里引入了一个中间存储器,叫作缓存,使用快速而又昂贵的 SRAM ,这个东西的速度能大大减少 CPU 等待数据时间。
因为昂贵,那么能存在 Cache 里面的数据只能是少量的,那么 Cache 是怎么知道 CPU 需要内存的哪些数据呢?
这里是根据局部性原理,分为空间局部性和时间局部性,空间局部性就是当前使用的数据的周围数据很有可能未来被使用,例子就是数组数据。时间局部性就是当前使用的数据很有可能未来被使用,例子就是循环变量。
通过局部性原理来设计预测算法,提高 CPU 所需数据在 Cache 里面的命中率,从而提高整体的存储结构的性能。
这里计算 Cache 的效率取决于 Cache 速度和命中率,都很好理解,就不单独解释了。
Cache 工作原理
内存 -> Cache
内存和 Cache 进行一次数据交换的单位是 Cache Line 的大小,需要一个存储单元的数据就将这个存储单元所属于的以 Cache Line 大小分的小组的全部成员全部放到 Cache 中,这也是局部性原理的体现。而内存以 Cache Line 的大小划分为单元,被称为内存 Line 。
下面主要是介绍内存中数据是放置到 Cache 中的哪些数据,并且是如何识别是否为 CPU 想要的数据的。
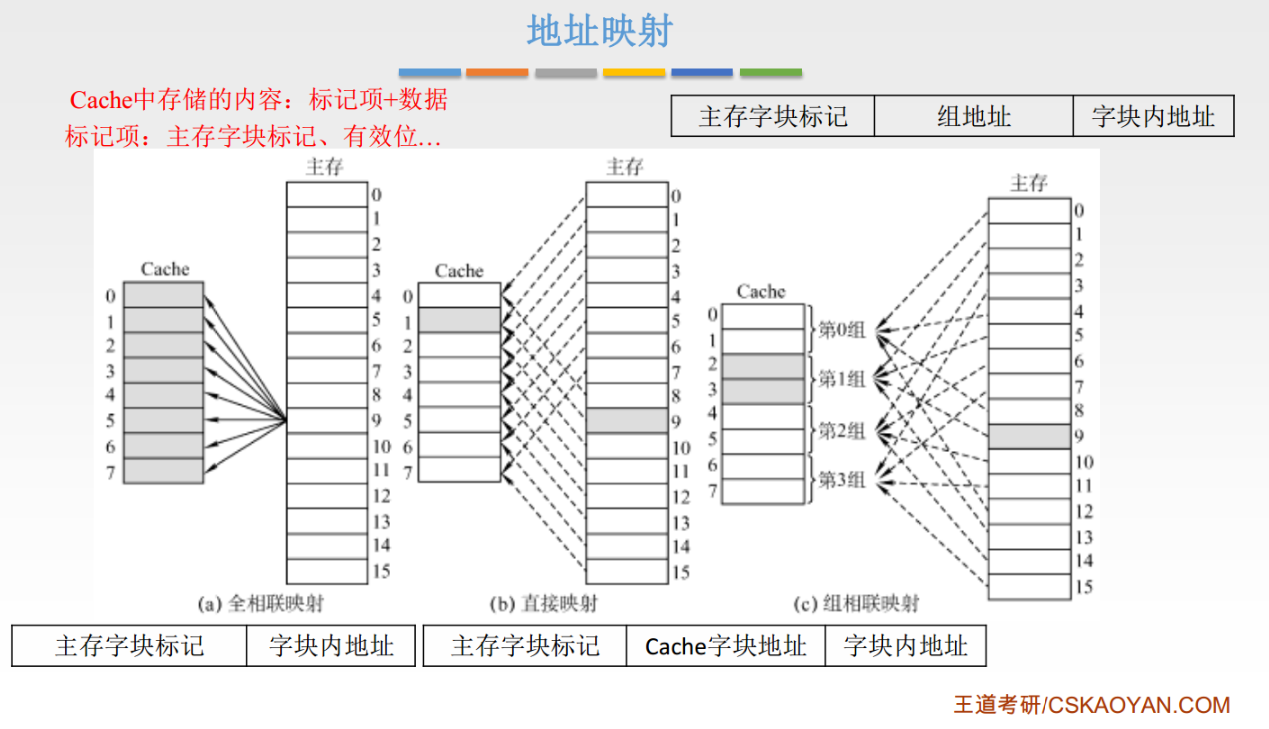
全相联映射
全相联映射指的是所有的内存和 Cache 映射都是采用相联映射方式,也就是根据在 Cache 行开头标记的内存地址前几位来确定在内存中的位置(用比较器来根据内容映射)。因此采用全相联映射的 Cache 可以将内存中的数据随意放置。
需要放置到 Cache 的数据,依次从 Cache 中寻找空位,如果有,就直接放进去。假设 Cache 大小为 512B(2^17),有八条 Cache Line 每条大小为 64B(2^14),于其进行数据交换的内存大小为 256MB(2^36),则:
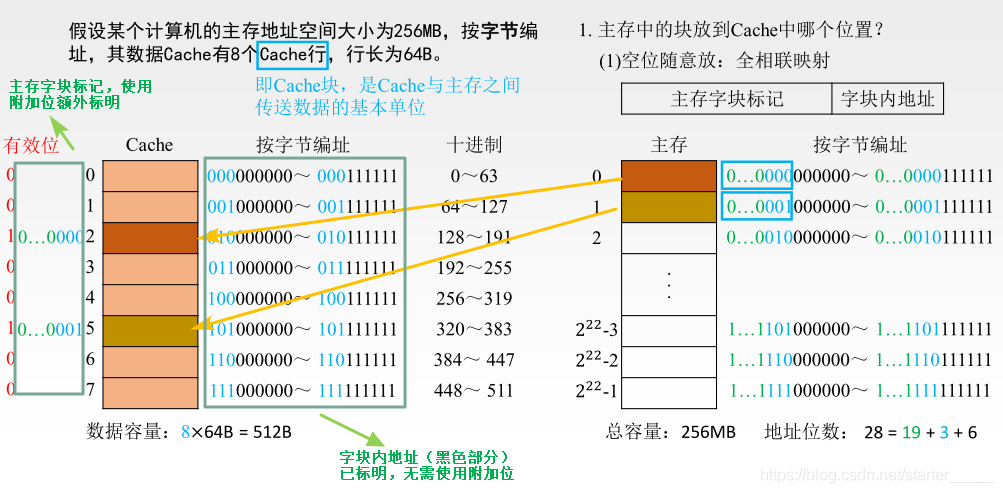
需要有效位 1 位,用来表示这个位置是否已经存在数据,1 表示有数据,0 表示没有数据。
需要内存 Line 编号 22 位(36-14),确定这个 Cache Line 里面的数据是属于内存的哪一块区域的,直接截取里面任意数据内存地址的前 22 位,其值即为内存 Line 的编号。
需要 17 位来存放一个 Cache Line 单位的内存数据,用来和 CPU 进行快速数据读写。
CPU 去命中数据只需要先去找内存 Line 编号是否存在,如果存在则直接按照地址后 17 位从所在的 Cache line 中读取即可。
优势:利用空余位置比较灵活,看到空位就可以直接使用。
劣势:Cache Line 为了定位差找里面数据对应内存的位置,需要有设计较为复杂的比对电路。
直接映射
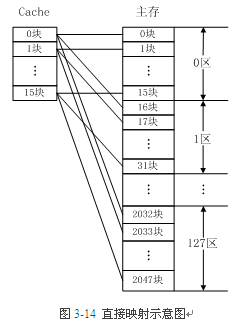
直接映射就好办了,我们将内存 Line 分为 Cache Line 数量个的小组(意味着属于这个小组的内存 Line 数据会放到小组所需与的 Cache Line 中)
将小组内部的的内存 Line 的后几位作为在小组里面的编号(从 0 到 最大数量-1),记录到 Cache Line 前面,用来定位里面的数据具体属于这个小组里面的那个成员的。
优势:因为一个 Cache Line 中的数据内存建立了严格的位置映射关系,所以 CPU 差找数据方便快速,不用设计复杂的对比电路。
劣势:因为一个内存 Line 映射的 Cache Line 只有一个位置,所以需要频繁的更替数据,灵活性差。
组相联映射
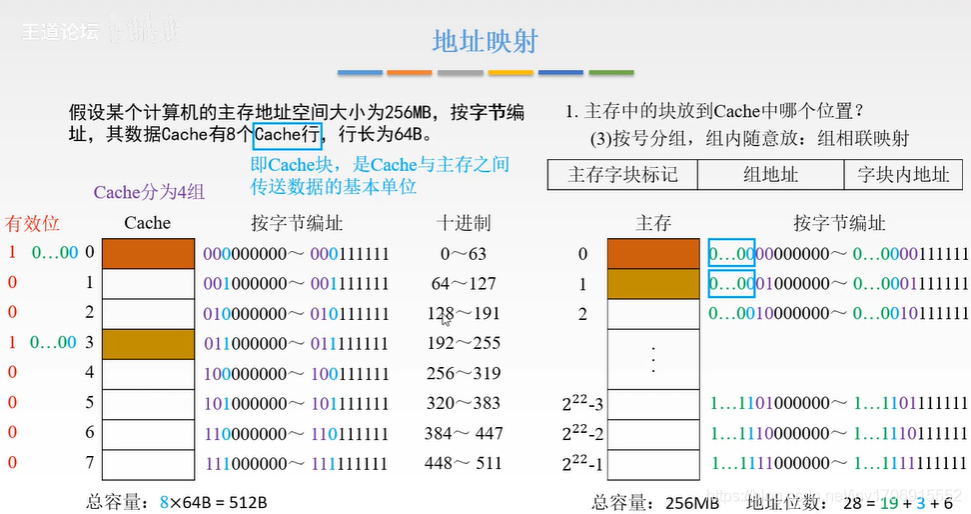
组相联映射的意思就是以小组划分的方式映射位置(根据位置映射),小组而内部采用相联映射(根据内容映射)。
这种方法是将上面的两种方法结合起来(老经典了),先分组,但是每一组里面有多条 Cache Line,这些可以被所属于此分组的内存 Line 数据随意放入。
这样就结合了上面两者的优点。
最后总结一下上面的三种映射方式:
Cache 满了处理
当内存的数据放入 Cache 中时,发现已经没有位置了,那么对于有多个可选择的替换位置,该替换哪个位置的数据呢?下面介绍四种算法。
- 随机算法 RAND
Random,虽说是随机,但是还是有一些算法的,这里需要参考操作系统相关。
- 先进先出算法 FIFO
First In First Out,使用队列实现,找出最早加入 Cache 的数据,将其替换。
- 近期最少使用 LRU
Least Recently Used,使用计数法,所有的数据都随着 CPU 访问而加一,如果数据被 CPU 命中,则计数清零。找出里面数据最大的,就是近期最少被命中的数据,将其替换,如果有多个最大,使用 FIFO 原则。
- 最不经常使用 LFU
Least Frequency Used,使用计数法,被 CPU 命中则加一,找出命中次数最少的,将其替换,如果有多个最小,则参看操作系统相关内容。
Cache 内存数据同步
当 CPU 需要修改内存中的数据,那么 Cache 和 内存 之间的数据如何同步呢,下面是几种方法。
写回法 Write-Back:Cache 被命中:CPU 修改 Cache 内的数据之后,暂不做处理,当整行 Cache Line 被替换之后,再将里面被修改的数据更新到内存中。
全写法 Write-Through:Cache 被命中:CPU 修改 Cache 内的数据之后,将被修改的数据加入到写缓冲区中,缓冲区慢慢的去内存中更新数据。
写分配法 Write-Allocate:Cache 无数据:将内存数据调入 Cache 中,在 Cache 中修改数据。
非写分配法 No-Write-Allocate:Cache 无数据:直接在内存中修改数据,不调入 Cache 中。
一般来说,会让写回法和写分配法结合,大大减少了内存的读写,但是两者数据之间往往不同。
剩下的就是全写法和写分配法结合,借助写缓冲区 Write Buffer,提升两者数据的同步率,但是会对内存进行频繁的读写。
重点来了,现代 CPU 当然是会考虑到它们之间的各自优劣性,所以就将这两种组合了起来,第二种结合方法作为 L1 Cache 和 L2 Cache 数据同步的方法,第一种结合方法作为 L2 Cache 和内存之间的数据同步方法。
这样更快的 L1 和 L2 能快速的完成数据修改
虚拟存储器
首先遇事不决,先看一篇非常棒的文章:深入虚拟内存
因为一般来说我们用户运行的程序,调用的程序/数据的位置都是在硬盘中的,能够得到的指令/数据地址也都是硬盘中的地址(我们称为虚拟地址)。而和 CPU 进行数据交换的,一般都是在内存中。所以我们需要将用到的指令和数据根据 IO 总线读取到内存中,CPU 去调用这些指令和数据是,因为只知道它在硬盘中的地址,不知道被读取到内存的那个位置了,因此我们在将硬盘的东西写入内存中的时候,就需要建立一个映射表,供 CPU 映射查找数据在内存中的真实地址。
里面具体的内容有很多,具体看上面的文章吧,写的非常好,本质上主存也是对硬盘的一个缓存优化,内存中存储程序最近运行会用到的数据,用页表来管理缓存映射,如果 CPU 命中就调用内存数据,没有命中就将硬盘数据调入内存中,CPU 再次去页表找映射最终命中。