BookStore 项目记录
关于我跟着视频做了一个小小的 Java Web 项目这件事
其实这个项目已经很久之前就做好了,但是由于各种的拖延症,导致了现在才开始总结,不过应该没有遗忘太多,所以还好。
项目结构
大概的结构:
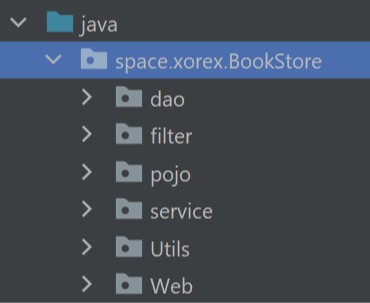
项目的思路就是 MVC 分层,分为 Model View Controller 三层,然后分别完成对应的任务。
DAO 层
持久化层比较让我记忆深刻的就是使用了 JDBCUtils BaseDao DetialsDao 三层来实现代码复用和解耦。
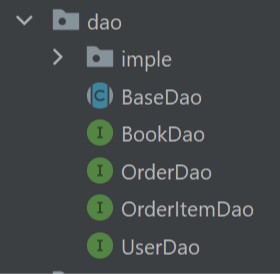
- 首先使用 JDBCUtils 工具类来负责数据库连接池的创建和管理,用于外界控制获取数据库连接和事务的实现,专注于和数据库的直接联系:
1 | public class JDBCUtils { |
- 然后使用了 BaseDao 对最基本的数据库交互做了封装,这里基本交互是指根据 SQL 查寻的返回值类型抽象出来一类查询,并使用了 DBUtils 来作为 SQL 查询结果和 Java Bean 数据封装之间转换的桥梁。
1 | public abstract class BaseDao { |
- 最后就是我们业务需要的针对于具体表的 SQL 执行的 DAO 了,只需要继承于 BaseDao 来复用基本数据库交互代码,自己只需要专注于构造具体业务的 SQL 语句即可,执行交给前两层。
1 |
|
Service 层
Service 层,主要任务就是通过调用 DAO 层,来实现项目的一个个最小单位的服务,用于提供给 Servlet 层组合调用,完成一个 Web 请求的执行。比如下面的都是关于订单的最小单位的服务。
1 | public interface OrderService { |
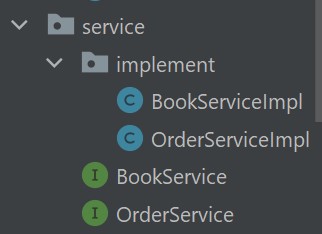
Servlet 层
Servlet 层主要是对用户发起的 Web 请求进行处理,通过组合调用 Service 层来实现这个请求。这里最亮眼的就是使用了反射来管理大量的请求。
首先创建一个 BaseServlet 来管理的 post get 请求,然后外部在发起请求的时候,带上需要处理请求的 Servlet 程序的名字。请求发送到 BaseServlet 之后,就会根据带来的 Servlet 程序名称通过反射调用对应的 Servlet 的方法,来完成请求处理。
1 |
|
然后其他的所有的 Servlet 类继承这个 BaseServlet,就能通过反射被调用自己的业务方法了。因为被继承之后,反射代码是在每一个子类里面执行的,所以也不需要担心方法名和其他 Servlet 程序重名的问题。
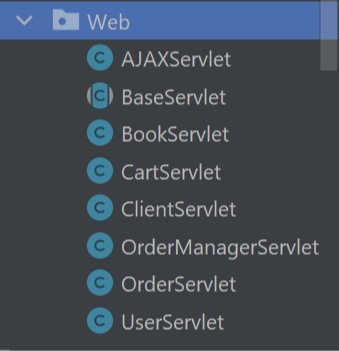
POJO 目录
这里先来讨论以下关于 POJO 和 Java Bean 的关系。
POJO Plain Ordinary Java Object 指的是简单普通的 Java 对象,只有纯粹的 setter/getter 方法的类被称为 POJO。这里的存粹就是只能有这两种方法,POJO 一般作为数据的载体。
Java Bean 则具有严格的规范,
所有的实例变量都应该是 private 类型(封装原则)
需要提供 public 修饰的无参构造方法(为了创建实例)
为 private 修饰的字段提供 setter/getter (为了获取和设置字段的值)
当然只需要满足上面三点即可,意味着 Java Bean 里面可以有除了 setter/getter 以外的方法(toString、hashCode 等),也可以实现各种接口(Serializable 等)
这里总结一下就是这两个东西很相近,但是又不兼容,POJO 专注于数据的简单存取,而 Java Bean 不仅仅能数据存取,还能进行简单的数据处理。
所以在项目里面这个层的作用就是作为数据的存储容器。
Utils 目录
里面主要是常用的代码封装出来的两个工具,一个是关于 JDCB 代码封装的 JDBCUtils,另外一个是将请求字符串数据转化为其他类型的 WebUtils 。
项目感受
其实这个可以说是我写代码以来第一个真正意义上的项目了(Python 那个小游戏算半抄半写的,基本上没学到啥东西),写这个更多意义上是想要做一个总结,当然可能是因为里面很多东西在做项目的时候都已经想明白了,所以这个总结也没多大的学习方面的作用。但是还是觉得想要把它认真的记录下来,留作纪念吧。